
Large Language Models (LLMs) have revolutionized conversational interactions, but remain generalist, which can lead to skewed responses. Retrieval Augmented Generation (RAG) technology integrates external sources into generated responses to address this. This article explores GraphRAG, a promising variant that leverages knowledge graphs to manage complex relationships and double accuracy in specific sectors, enabling specialized AI assistants without retraining models.
Date: 10 April 2025
Expertises
Domaine
Innovation theme
About project
Author
Large Language Models (LLMs) have revolutionized natural language processing in recent years. Their ability to understand and generate text in a fluid and contextual manner has transformed conversational assistants. Unlike older chatbots based on fixed rules, modern solutions like ChatGPT ChatGPT and LeChat offer natural conversations according to context, adapting to nuances and communication styles [1]. However, despite their prowess, these models still present challenges, notably their tendency to produce incomplete responses or hallucinations (incorrect statements) [2].
Retrieval Augmented Generation (RAG) technology has become a promising solution allowing efficient document querying to improve the factuality of responses. Indeed, instead of relying solely on the model’s internal knowledge, RAG incorporates external sources into the LLM’s context when generating responses [3]. This approach avoids the constraints of fine-tuning (adjusting the model by training it on a specific dataset), which requires significant resources and can lead to a loss of previous capabilities, particularly when new information contradicts the model’s preexisting knowledge [4] [5].
This article will explore a promising variant called Graph Retrieval-Augmented Generation (GraphRAG). This method enriches the traditional RAG approach by creating and leveraging knowledge graphs. Before introducing this new architecture, we will begin with a brief reminder of the theoretical foundations of RAG systems, followed by an analysis of their inherent limitations.
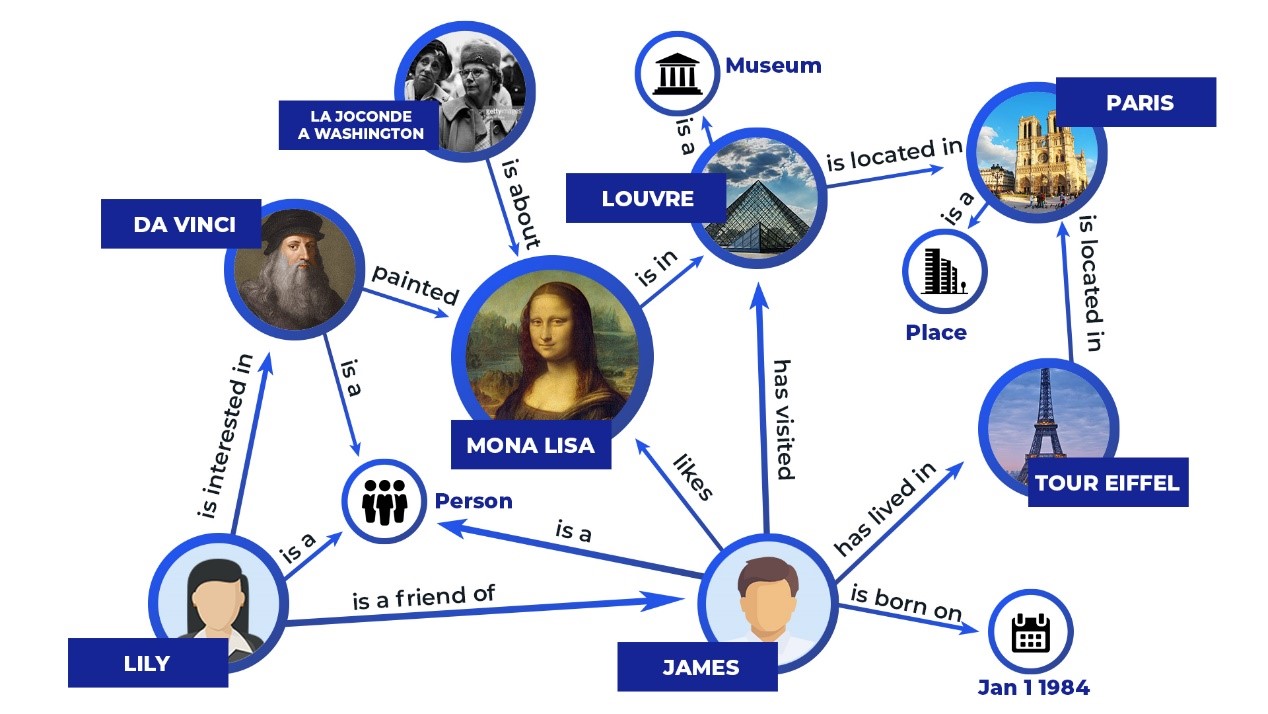
2.1 Traditional RAG Architecture
The traditional RAG architecture (referred to in literature as "naive RAG" or "vanilla RAG") is an approach aimed at improving the relevance and factuality of generated responses by giving the LLM access to pertinent external information while leveraging its capabilities. To achieve this, it integrates user queries with a set of relevant documents from a vector database, as shown in the illustration below:
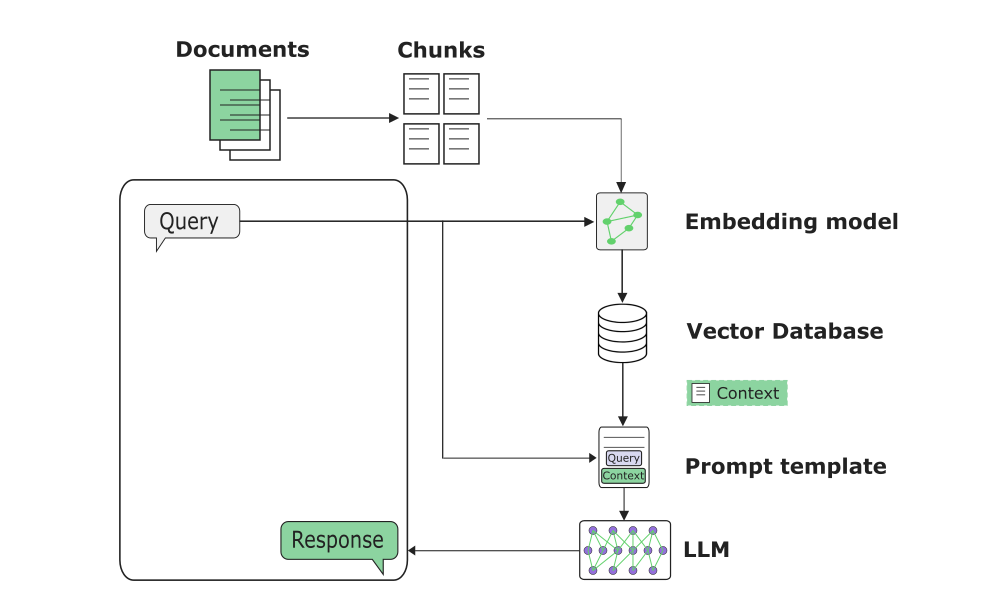
Before any query, a preparation step of the knowledge base is necessary. Documents are transformed into vectors (numerical representation of their content) and stored in a vector database. This step allows structuring the data to facilitate querying.
When a user asks a question, the system processes this request in two key successive steps. First, during the initial phase, called the retrieval step, it transforms the user’s question (query) into a vector and compares it to vectorized text fragments to identify and retrieve the most relevant data (passages most similar to the question).
Next comes the augmented generation phase (generation step), where the system combines relevant text fragments with the user’s question. This step creates an "enriched prompt" containing both the question and this additional information. Finally, the model generates a response by drawing on two sources of knowledge: the specific information provided in the context (the retrieved text fragments) and its general knowledge acquired during its training phase.
To deepen your understanding of these systems, you can consult a previous article dedicated to this specific subject [6].
2.2 Inherent Limitations of Traditional RAG
Traditional RAG has shortcomings due to its linear representation of data. Indeed, it treats documents as a simple sequence of words or sentences, analyzing each piece of text independently without establishing connections between different sources. This fragmented approach distributes complete information across multiple passages, preventing the system from grasping the deep structure of information and their complex relationships.
First, traditional RAG systems do not appropriate the knowledge contained in relationships. Indeed, segmenting documents into independent chunks leads to a loss of transversal semantic relationships [7], meaning logical links between dispersed information (for example, links between a medication and its side effects, or how these effects interact with other treatments). This results in difficulties retrieving information about relationships between multiple concepts and documents.
Next, there can be a loss of contextual dependencies necessary to maintain coherence between multiple text extracts [8]. This problem occurs when essential information is dispersed in different parts of a document, creating implicit links that the system struggles to reconstruct. For example, if an excerpt mentions a controversial economic reform without clearly identifying its author, a RAG might attribute this policy to the wrong leader or country. This confusion is even more likely as LLMs generally have a knowledge base that stops before the current year, preventing them from accessing the most recent information to establish the right contextual connections. It’s possible to mitigate this problem with different segmentation strategies (such as separation into chunks with text redundancy) but the problem persists.
Additionally, there is a lack of global information. Indeed, it is complex for such a system to process queries requiring multi-relational reasoning and therefore to have the overall view necessary to answer more general questions. For example, analyzing the causes of a stock market crash requires connecting several interdependent domains: financial market fluctuations, consumer behavior, international economic policies (such as a trade war between countries), and their cascading effects that can lead to a recession. This global understanding far exceeds the isolated analysis of concepts related to financial markets. There are methods to try to improve the understanding of complex queries (for example, the integration of document metadata [9]), but it’s still limited by the "style" of text chunking and remains difficult to respond to queries requiring "multi-hop" navigation between these chunks.
Finally, redundancy of information is a major challenge for RAG systems [10]. Indeed, they must process large volumes of unstructured text and tend to repeat text snippets when concatenating sources in prompts, especially when multiple documents cover the same subject. This excessively lengthens the context, making essential information less accessible (the "lost in the middle" dilemma [11]). Furthermore, this redundancy increases retrieval costs, limits system scalability, and reduces overall efficiency, despite existing optimization efforts [12].
3.1 GraphRAG architecture
Unlike traditional RAG which operates on linear text chunks, GraphRAG exploits the topology of knowledge graphs [13] to capture underlying links, allowing it to respond to complex queries requiring a deep understanding of concepts and relationships presented in the corpus. Modeling dependencies between nodes facilitates the discovery of related knowledge elements around a central subject or entity. This approach improves search by allowing navigation through relevant paths while pruning non-essential information during the process, which can be summarized in three main steps (diagram below).
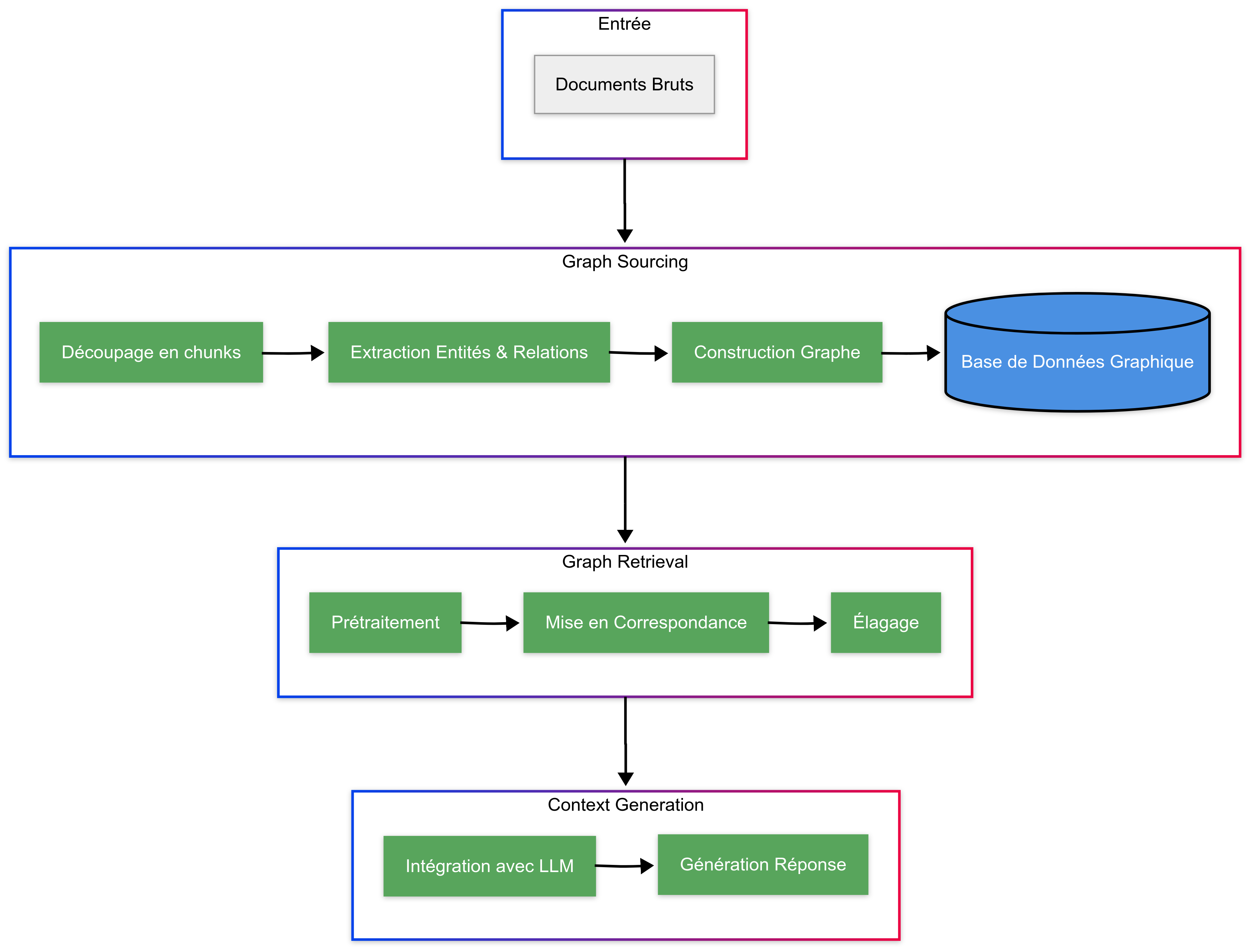
Step 1: knowledge organization (Graph Sourcing)
This step transforms raw data into graph structures before extracting and integrating relevant information to answer queries. Knowledge graphs (KG) have existed for a long time, but GraphRAG’s major innovation lies in automating the Graph Sourcing process through LLMs. This can be divided into 3 parts:
Step 2: knowledge retrieval (Graph Retrieval)
This step serves to extract relevant information from a knowledge graph according to the user’s query. There are different types of strategies and retrieval techniques, but we will discuss these further in a future article. The general knowledge retrieval process can be broken down into three main phases:
1. Preprocessing
2. Matching
3. Pruning
Step 3: knowledge integration (Context Generation)
This phase incorporates graphical information into LLMs to improve the quality of generated responses. It is carried out according to two main approaches: either by retraining the LLM with new knowledge (fine-tuning), or by enriching the context provided to the LLM during its use (in-context learning). This second method proves particularly interesting when retraining is not possible, especially in the case of proprietary close-source LLMs.
3.2 Advantages over traditional RAG
GraphRAG represents an interesting evolution compared to traditional RAG systems, bringing improvements that transform how the LLM interacts with information. By incorporating knowledge graphs within augmented search systems, this method overcomes many constraints inherent to the classic system. Let’s examine in detail the advantages offered by this innovation.
First, its ability to create a rich and nuanced semantic representation of information. By capturing complex relationships between concepts, it allows identification of implicit dependencies, contextualization of ambiguous information, and identification of pivot entities within knowledge networks.
Next, it helps reduce hallucinations. Indeed, its performance speaks for itself: in a recent benchmark [14], it achieved an accuracy (rate of correct answers) of 81.67%, compared to only 57.50% for classic vector methods on general questions. This improvement is even more striking in specific domains such as industry, where it nearly doubles this rate, going from 46.88% to 90.63%, thus demonstrating its superior capacity for contextualization and interpretation.
Finally, its operational efficiency is also notable. By relying on a graph structure, GraphRAG manages to significantly reduce its token consumption, achieving up to 97% reduction [15]. Moreover, certain versions of GraphRAG (such as LightRAG [16]) allow updates without complete reindexing, although it should be noted that this is not the case for all GraphRAG implementations, which sometimes require rebuilding the entire graph.
Additionally, it offers improved explainability. This approach provides good interpretability by allowing tracing of the path that led to the system’s final answer. Visualizing the paths taken by the system thus offers a clear and detailed understanding of its internal logic.
4.1Current Limitations
Although representing a significant advance in response generation, GraphRAG faces several important challenges that limit its adoption and effectiveness in the real world.
First, graph generation constitutes a major initial obstacle due to its cost. This operation requires multiple calls to APIs (such as OpenAI), which entails significant expenses. For example, for a relatively modest corpus of 32,000 words, using GPT-4o for graph generation can reach a cost of 7 dollars. Although this operation is only necessary once for each corpus, this initial cost can represent a significant barrier for projects with limited resources.
Furthermore, the time required for this initial graph construction is also problematic. This phase can extend over several hours, which considerably slows down the deployment of solutions based on GraphRAG and limits reactivity in the face of rapidly evolving corpora.
Then, even once the graph is created, daily use of the system is not exempt from constraints either. Latency could prove problematic for queries requiring multi-hop analyses in complex graphs. On the same corpus of 32,000 words mentioned previously, processing a simple user query can sometimes take about ten seconds, which negatively affects the user experience and limits use cases requiring real-time responses.
Moreover, one of the limitations of certain GraphRAG solutions is their inability to provide complete traceability of sources. Although they extract relevant fragments to generate their responses, these solutions often omit precisely identifying the origin of information (document titles, page numbers). This limitation compromises the verifiability of information and considerably reduces the usefulness of these systems in contexts requiring documentary rigor. It should be noted, however, that this limitation does not apply to all graph solutions.
Finally, there is a strong dependence of GraphRAG’s effectivenesson the quality of its underlying ontology, and therefore on the instructions (or KG) used to generate it. A graph built on an unsuitable or incomplete base will not be able to fully exploit the potential of this approach, and could therefore compromise the quality of the results obtained.
4.2 Promising research directions
To overcome these challenges while preserving the advantages already mentioned, let’s now focus on several strategic improvement paths that deserve our attention.
First, to make this system more suitable for real-time applications, several solutions exist. For example, focusing on reducing computational complexity and necessary resources by using LightRAG [17], or optimizing how resources are used, without necessarily reducing them, via Fast GraphRAG [18], which focuses on asynchronous operations and parallelized queries to increase execution speed.
Next, to further increase the quality of generated results, integration of models capable of handling wider contexts should be explored in the case of graphs. For example, LongRAG [19], which allows using contexts of about 3000 words, could be combined with LightRAG [20] to accumulate the advantages of each.
Finally, there also remains the possibility of using Agent RAG [21], particularly via an orchestrator LLM capable of selecting the most appropriate graph according to the question asked.
GraphRAG represents a significant advance compared to traditional RAG methods, offering increased relevance of generated results. Its strength lies notably in its ability to answer transversal questions and highlight implicit links. Existing GraphRAG solutions, despite their limitations, pave the way for future advances aimed at optimizing its performance. Thus, its integration in business involves a compromise on latency: currently to be avoided for systems requiring an instantaneous response but perfectly appropriate when a delay of a few seconds is acceptable.
[13] https://neo4j.com/blog/genai/what-is-knowledge-graph/#:~:text=A%20opens%20in%20new%20tab,events%2C%20situations%2C%20or%20concepts.