
Les Large Language Models (LLMs) ont révolutionné les interactions conversationnelles, mais restent généralistes, ce qui peut amener à des réponses faussées. Pour y remédier, la technologie Retrieval Augmented Generation (RAG) intègre des sources externes aux réponses générées. Cet article explore GraphRAG, une variante prometteuse qui exploite les graphes de connaissance pour gérer les relations complexes et doubler la précision dans certains secteurs, permettant des assistants IA spécialisés sans réentraînement des modèles
Date: 10 avril 2025
Domaine
Thème d'innovation
A propos du projet
Auteur
Ces dernières années, les Large Language Models (LLMs) ont révolutionné le traitement automatique du langage. Leur capacité à comprendre et à générer du texte de manière fluide et contextuelle a transformé les assistants conversationnels. Contrairement aux anciens chatbots basés sur des règles fixes, les solutions modernes comme ChatGPT et LeChat offrent des conversations naturelles selon le contexte, s’adaptant aux nuances et aux styles de communication [1]. Cependant, malgré leurs prouesses, ces modèles présentent encore des défis, notamment leur tendance à produire des réponses incomplètes ou avec hallucinations (affirmations incorrectes) [2].
La technologie de Retrieval Augmented Generation (RAG) est devenue une solution prometteuse permettant d’interroger efficacement des documents afin d’améliorer la factualité des réponses. En effet, au lieu de s’appuyer uniquement sur les connaissances internes du modèle, le RAG intègre des sources externes dans le contexte du LLM lors de la génération de réponses [3]. Cette approche évite les contraintes du fine-tuning (ajustement du modèle en l’entrainant sur un dataset spécifique) qui nécessite d’importantes ressources et qui peut entraîner une perte de capacités antérieures, particulièrement lorsque les nouvelles informations contredisent les connaissances préexistantes du modèle [4] [5].
Dans cet article, nous allons explorer une variante prometteuse appelée GraphRAG (Graph Retrieval-Augmented Generation). Cette méthode enrichit l’approche RAG traditionnelle en créant et en exploitant des graphes de connaissances. Avant d’introduire cette nouvelle architecture, nous commencerons par un bref rappel des fondements théoriques des systèmes RAG, suivi par une analyse des limites inhérentes à ces derniers.
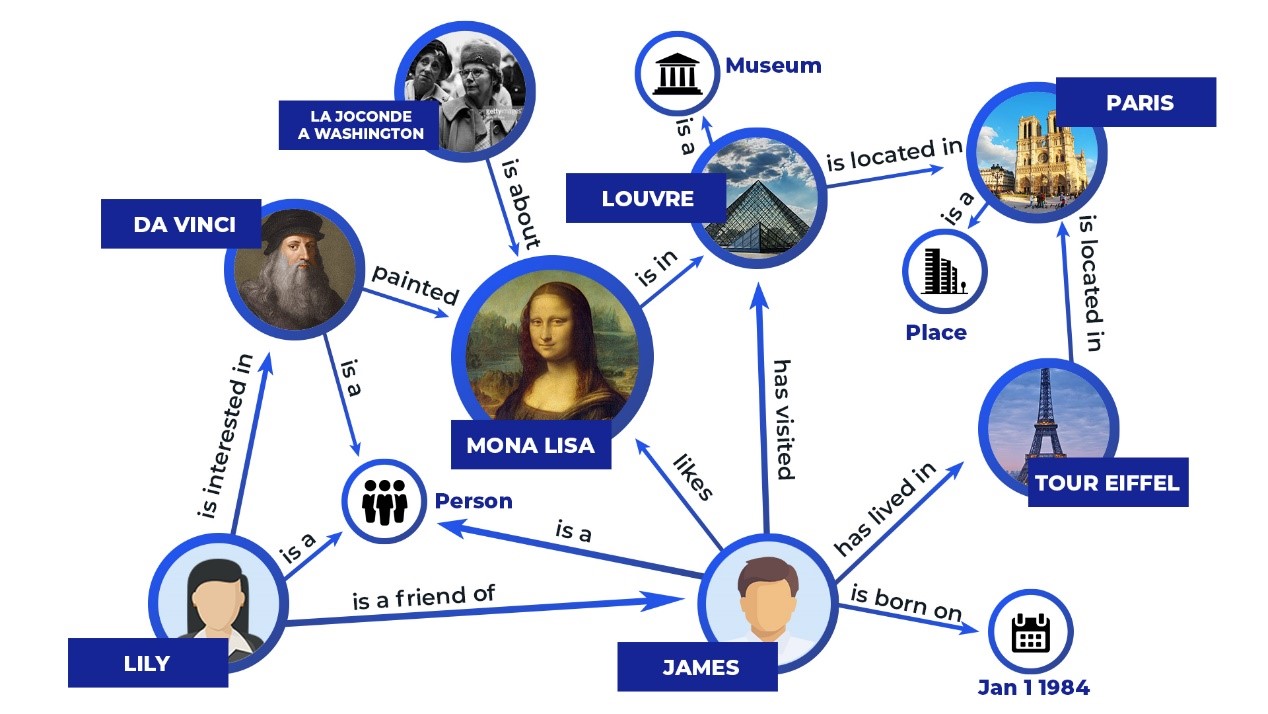
2.1 Architecture du RAG traditionnel
L’architecture RAG traditionnelle (appelée dans la littérature “naïve RAG” ou “vanilla RAG”) est une approche visant à améliorer la pertinence et la factualité des réponses générées en donnant accès à des informations externes pertinentes au LLM, tout en exploitant ses capacités. Pour cela, il intègre les requêtes des utilisateurs à un ensemble de documents pertinents provenant d’une base de données vectorielle, comme on peut le voir dans l’illustration ci-dessous :
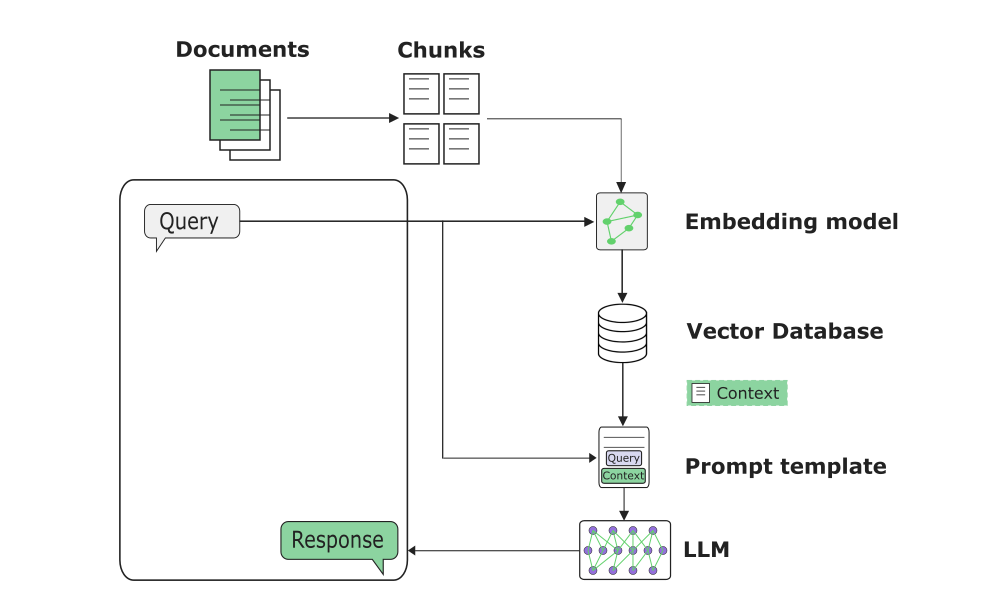
Avant toute interrogation, une étape de préparation de la base de connaissances est nécessaire. Les documents sont transformés en vecteurs (représentation numérique de leur contenu) et stockés dans une base de données vectorielle. Cette étape permet de structurer les données afin de faciliter leur interrogation.
Lorsqu’un utilisateur pose une question, le système traite cette demande en deux étapes clés qui se succèdent. Dans un premier temps, lors de la première phase, appelée recherche contextuelle (retrieval step), il transforme la question de l’utilisateur (requête) en vecteur et le compare aux fragments de textes vectorisés afin d’identifier et de récupérer les données les plus pertinentes (passages les plus similaires à la question).
Dans un second temps intervient une phase de génération augmentée (generation step), où le système combine les fragments de textes pertinents avec la question de l’utilisateur. Cette étape permet de créer un "prompt enrichi" qui contient à la fois la question et ces informations supplémentaires. Pour finir, le modèle génère une réponse en s’appuyant sur deux sources de connaissances : les informations spécifiques fournies dans le contexte (les fragments de textes récupérés) et ses connaissances générales acquises pendant sa phase d’entraînement.
Pour approfondir votre compréhension de ces systèmes, vous pouvez consulter un article antérieur dédié à ce sujet spécifique [6].
2.2 Limites inhérentes au RAG traditionnel
Le RAG traditionnel présente des lacunes, de par sa représentation linéaire des données. En effet, il traite les documents comme une simple séquence de mots ou phrases, analysant chaque bout de texte indépendamment sans établir de connexions entre les différentes sources. Cette approche fragmentée répartit l’information complète sur plusieurs passages, ce qui empêche le système de saisir la structure profonde des informations et leurs relations complexes.
Tout d’abord, les systèmes RAGs traditionnels ne s’approprient pas les connaissances contenues dans les relations. En effet, la segmentation des documents en morceaux indépendants (chunks) entraîne une perte des relations sémantiques transversales [7] , c’est-à-dire des liens logiques entre des informations dispersées (par exemple, les liens entre un médicament et ses effets secondaires, ou comment ces effets interagissent avec d’autres traitements). Cela entraîne des difficultés à retrouver les informations concernant les relations entre plusieurs concepts et documents.
Ensuite, il peut y avoir une perte des dépendances contextuelles nécessaires pour maintenir une cohérence entre plusieurs extraits de texte [8]. Ce problème survient lorsque des informations essentielles sont dispersées dans différentes parties d’un document, créant des liens implicites que le système peine à reconstituer. Par exemple, si un extrait mentionne une réforme économique controversée sans identifier clairement son auteur, un RAG pourrait attribuer cette politique au mauvais dirigeant ou pays. Cette confusion est d’autant plus probable que les LLMs ont généralement une base de connaissances qui s’arrête avant l’année en cours, les empêchant d’accéder aux informations les plus récentes pour établir les bonnes connexions contextuelles. Il est possible d’atténuer ce problème avec différentes stratégies de segmentation (comme la séparation en chunks avec redondance de texte) mais le problème persiste.
De plus, il y a un manque d’informations globales. En effet, il est complexe pour un tel système de traiter des requêtes nécessitant un raisonnement multi-relationnel et donc d’avoir la vue d’ensemble nécessaire pour répondre à des questions plus générales. Par exemple, analyser les causes d’un krach boursier exige de connecter plusieurs domaines interdépendants : les fluctuations des marchés financiers, le comportement des consommateurs, les politiques économiques internationales (comme une guerre commerciale entre pays), et leurs effets en cascade pouvant conduire à une récession.
Cette compréhension globale dépasse largement l’analyse isolée des concepts liés aux marchés financiers. Il existe des méthodes pour essayer d’améliorer la compréhension de requêtes complexes (par exemple l’intégration des métadonnées des documents [9]) mais c’est toujours limité par le “style” de découpage des textes et reste difficile de répondre à des requêtes nécessitants une navigation “multi-sauts” entre ces chunks.
Enfin, la redondance des informations est un défi majeur pour les systèmes RAG [10]. En effet, ils doivent traiter d’importants volumes de texte non structuré et ont tendance à répéter des bribes de textes lorsqu’ils concatènent les sources dans les prompts, notamment lorsque plusieurs documents traitent d’un même sujet. Cela allonge excessivement le contexte, rendant des informations essentielles moins accessibles (dilemme du « lost in the middle » [11]). Par ailleurs, cette redondance augmente les coûts de récupération, limite l’évolutivité du système et réduit son efficacité globale, malgré les efforts d’optimisation existants [12].
3.1 Architecture du GraphRAG
Contrairement au RAG traditionnel qui opère sur des chunks textuels linéaires, le GraphRAG exploite la topologie des graphes de connaissance [13] afin de capturer les liens sous-jacents, ce qui permet de répondre à des requêtes complexes nécessitant une compréhension approfondie des concepts et relations présentés dans le corpus. La modélisation des dépendances entre les nœuds facilite la découverte d’éléments de connaissance connexes autour d’un sujet ou d’une entité centrale. Cette approche améliore la recherche en permettant de naviguer à travers des chemins pertinents tout en élaguant les informations non essentielles pendant le processus, qui peut se résumer en trois étapes principales (diagramme ci-dessous).
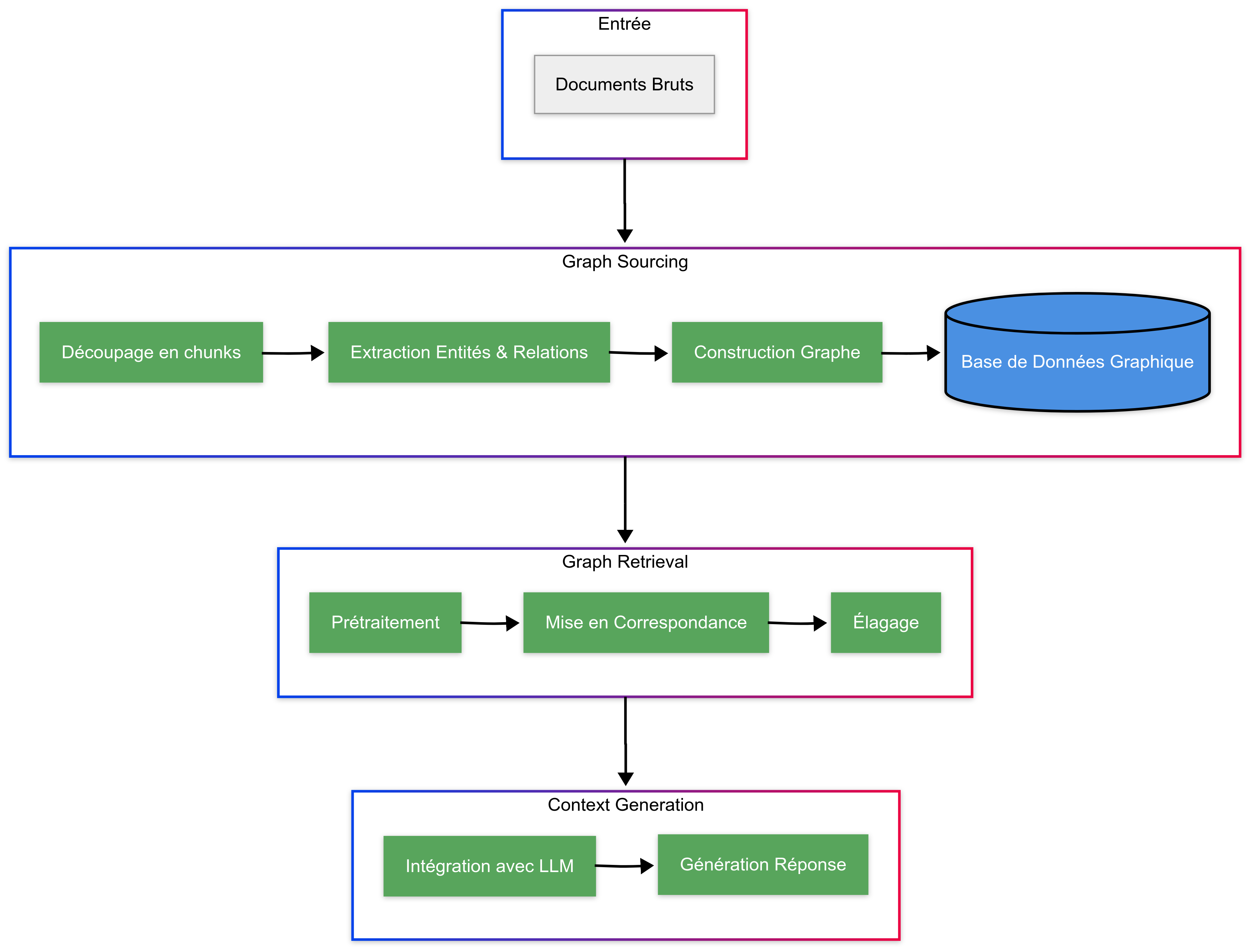
Etape 1 : organisation des connaissances (Graph Sourcing)
Cette étape transforme les données brutes en structures de graphe avant d’extraire et d’intégrer les informations pertinentes pour répondre aux requêtes. Les graphes de connaissances (Knowledge Graph - KG) existent depuis longtemps mais l’innovation majeure des GraphRAG réside dans l’automatisation, grâce aux LLMs, du processus de Graph Sourcing. Ce dernier peut être divisée en 3 parties :
Etape 2 : récupération des connaissances (Graph Retrieval)
Cette étape sert à l’extraction des informations pertinentes d’un graphe de connaissances selon la requête de l’utilisateur. Il existe différents types de stratégies et de techniques de récupération mais nous en discuterons davantage dans un futur article. Le processus général de récupération des connaissances peut se décomposer en trois phases principales
1. Prétraitement
2. Mise en correspondance (Matching) :
3. Élagage (Pruning)
Etape 3 : intégration des connaissances (Context generation)
Cette phase incorpore les informations graphiques dans les LLMs pour améliorer la qualité des réponses générées. Elle s’effectue selon deux approches principales : soit en réentrainant le LLM avec les nouvelles connaissances (fine-tuning), soit en enrichissant le contexte fourni au LLM lors de son utilisation (apprentissage en contexte). Cette seconde méthode se révèle particulièrement intéressante lorsque le réentrainement n’est pas possible, notamment dans le cas des LLMs propriétaires en close-source.
3.2 Avantages par rapport au RAG traditionnel
Le GraphRAG représente une évolution intéressante par rapport aux systèmes RAG traditionnels, apportant des améliorations qui transforment la façon dont le LLM interagit avec les informations. En incorporant les graphes de connaissance au sein des systèmes de recherche augmentée, cette méthode surmonte de nombreuses contraintes inhérentes au système classique. Examinons en détail les avantages offerts par cette innovation.
Tout d’abord, sa capacité à créer une représentation sémantique riche et nuancée des informations. En capturant les relations complexes entre les concepts, il permet d’identifier des dépendances implicites, de contextualiser des informations ambiguës et de repérer des entités pivots au sein des réseaux de connaissances.
Ensuite, il permet de réduire les hallucinations. En effet, ses performances parlent d’elles mêmes : lors d’un benchmark récent [14], il a atteint une exactitude (taux de réponses correctes) de 81,67%, contre seulement 57,50% pour les méthodes vectorielles classiques sur des questions générales. Cette amélioration est d’autant plus interpellante dans des domaines spécifiques comme l’industrie, où il double pratiquement ce taux, passant de 46.88% à 90,63, démontrant ainsi sa capacité supérieure de contextualisation et d’interprétation.
Pour finir, son efficacité opérationnelle est également notable. En s’appuyant sur une structure de graphe, le GraphRAG parvient à réduire significativement sa consommation de jetons, atteignant jusqu’à 97% de réduction [15]. De plus, certaines versions de GraphRAG (tel que LightRAG [16]), permettent les mises à jour sans réindexation complète mais il est tout de même à noter que ce n’est pas le cas de tous les graphRAG, qui nécessitent parfois de reconstruire l’entièreté du graphe.
De plus, il offre une explicabilité améliorée. Cette approche donne une bonne interprétabilité en permettant de retracer le cheminement qui a conduit à la réponse finale du système. La visualisation des chemins empruntés par le système offre ainsi une compréhension claire et détaillée de sa logique interne.
4.1 Limitations actuelles
Bien que représentant une avancée importante dans la génération de réponse, GraphRAG se heurte à plusieurs défis importants qui limitent son adoption et son efficacité dans le monde réel.
Tout d’abord, la génération des graphes constitue un premier obstacle majeur en raison de son coût. Cette opération nécessite de multiples appels à des APIs (comme OpenAI), ce qui entraîne des dépenses importantes. À titre d’exemple, pour un corpus relativement modeste de 32 000 mots, l’utilisation de GPT-4o pour la génération du graphe peut atteindre un coût de 7 dollars. Bien que cette opération ne soit nécessaire qu’une seule fois pour chaque corpus, ce coût initial peut représenter un frein important pour les projets disposant de ressources limitées.
Par ailleurs, le temps requis pour cette construction initiale du graphe pose également problème. Cette phase peut s’étendre sur plusieurs heures, ce qui ralentit considérablement le déploiement de solutions basées sur le GraphRAG et limite la réactivité face à des corpus en évolution rapide.
Ensuite, même une fois le graphe créé, l’utilisation quotidienne du système n’est pas non plus exempte de contraintes. La latence pourrait s’avérer problématique lors de requêtes nécessitant des analyses multi-sauts dans des graphes complexes. Sur le même corpus de 32 000 mots mentionné précédemment, le traitement d’une simple requête utilisateur peut parfois nécessiter une dizaine de secondes, ce qui affecte négativement l’expérience utilisateur et limite les cas d’usage nécessitant des réponses en temps réel.
De plus, l’une des limitations de certaines solutions de GraphRAG est leur incapacité à fournir une traçabilité complète des sources. Bien qu’elles extraient des fragments pertinents pour générer leurs réponses, ces solutions omettent souvent d’identifier précisément l’origine des informations (titres des documents, numéros de pages). Cette limite compromet la vérifiabilité des informations et réduit considérablement l’utilité de ces systèmes dans des contextes exigeant une rigueur documentaire. Il est toutefois à noter que cette limitation ne s’applique pas à l’ensemble des solutions de graphe.
Enfin, il y a une forte dépendance de l’efficacité du GraphRAG à la qualité de son ontologie sous-jacente, et donc des instructions (ou du KG) utilisés pour le générer. Un graphe construit sur une base inadaptée ou incomplète ne pourra pas exploiter pleinement le potentiel de cette approche, et donc pourrait compromettre la qualité des résultats obtenus.
4.2 Axes de recherche prometteurs
Pour surmonter ces défis tout en préservant les avantages déjà mentionnés, focalisons-nous maintenant sur plusieurs pistes d’amélioration stratégiques qui méritent notre attention.
Tout d’abord, pour rendre ce système plus adapté pour des applications temps réel, plusieurs solutions existent. Par exemple, se concentrer sur la réduction de la complexité de calcul et des ressources nécessaires en utilisant LightRAG [17], ou optimiser la manière d’utiliser les ressources, sans pour autant les réduire via Fast GraphRAG [18], qui s’oriente sur les opérations asynchrones et les requêtes parallélisées pour accroître la vitesse d’exécution.
Ensuite, pour augmenter davantage la qualité des résultats générés, l’intégration de modèles capables de traiter des contextes plus vastes est à approfondir dans le cas des graphes. Par exemple, LongRAG [19], qui permet d’utiliser des contextes d’environ 3000 mots, pourrait être combinée avec LightRAG [20] pour cumuler les avantages de chacun.
Pour finir, il reste également la possibilité d’utiliser des Agent RAG [21], notamment via un LLM orchestrateur capable de sélectionner le graphe le plus approprié selon la question posée.
Le GraphRAG représente une avancée significative par rapport aux méthodes RAG traditionnelles, offrant une pertinence accrue des résultats générés. Sa force réside notamment dans sa capacité à répondre à des questions transversales et à mettre en évidence des liens implicites. Les solutions GraphRAG existantes, malgré leurs limites, préparent le terrain pour des avancées futures visant à optimiser ses performances. Ainsi, son intégration en entreprise implique un compromis sur la latence : à éviter actuellement pour les systèmes nécessitant une réponse instantanée mais parfaitement appropriés lorsqu’un délai de quelques secondes est acceptable.
[13] https://neo4j.com/blog/genai/what-is-knowledge-graph/#:~:text=A%20opens%20in%20new%20tab,events%2C%20situations%2C%20or%20concepts.