
The beginning of 2023 has been marked by the emergence of a new technological tool in the public arena, namely ChatGPT, a chatbot presented as being able to respond to a wide variety of questions and requests made by anyone. While this tool is seen as a revolution by many, it is rather the result of the evolution of scientific research around the construction of dialogue between humans and machines, through human language. In this article, we provide an overview of this field and then discuss the specific case of ChatGPT. We will conclude with the related research activities within CETIC.
The term "chatbot" refers to a computer program capable of conversing with a user through human language. The origin of this term is generally associated with the test invented by Alan Turing in 1950. This test aims to evaluate the anthropomorphic capabilities of a machine: to what extent is it capable of conducting conversations indistinguishable from those of a human? This test, still in use today, has provided direction for the development of increasingly powerful chatbots. Initially, however, this experimentation domain remained confined to a small community of technology enthusiasts. Later, around the 2010s, the arrival of virtual assistants such as Siri, Alexa, Google Assistant, and Cortana popularized the notion of chatbot. Nowadays, chatbots are used in multiple fields such as customer service, the medical sector and education. Given their success, it can be reasonably expected that chatbots will become even more present in our daily lives. However, the strengthening of this man-machine proximity is not without risk, as a recent tragic event reminds us, namely the suicide of a Belgian in close contact with a chatbot [1]. Reflection is underway at the European Union level to strengthen the legal framework related to the use of these tools [2].
Over time, the way of designing chatbots has evolved, following the evolution of technology for processing human language by machines: from static rules to approaches based on statistical models such as deep learning. The diagram below shows a general architecture of chatbots, representative of the most common functionalities of chatbots, regardless of their degree of evolution.
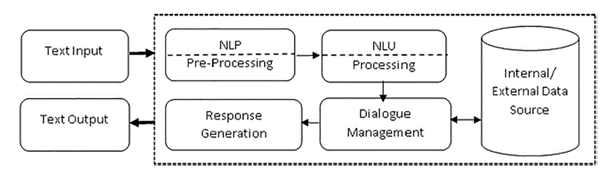
The functioning is as follows. The chatbot receives user input text. This text undergoes preprocessing to extract useful information for analysis (NLP - Natural Language Processing): converting everything to lowercase, removing punctuation marks, extracting the word root, etc. After this preprocessing, the process aims to identify the user’s intention and any relevant keywords related to that intention (NLU - Natural Language Understanding), such as searching for a pizza delivery service (intention) in the Brussels region (keyword). Once this step is completed, the formulation of the response to the user is based on an internal or external knowledge source to the chatbot. This response is finally transmitted to the user.
Our review of the scientific literature on chatbots highlights the following main distinctive features of chatbots. The most obvious criterion is the mode of communication with the user. Most chatbots communicate via text exchanges. However, some of them also communicate by voice or image or even in a hybrid way, allowing the user to choose the mode of communication.
Another distinctive feature is the chatbot’s area of expertise. It can be open or closed. In a closed domain, the chatbot is designed to only respond to requests relevant to that domain, such as after-sales service of an online shop. On the other hand, in an open domain, the chatbot is likely to receive any type of request from the user, without prior filtering.
A trait that is receiving increasing attention from the scientific community is the anthropomorphic ability of the chatbot. Beyond the relevance of the response to the given request, it is necessary to evaluate other skills typically associated with a human interlocutor, such as the ability to maintain a conversation, respond adequately to unwanted questions or highlight personality traits.
Another trait that has caught our attention is the way in which the chatbot’s knowledge is stored. This knowledge can be recorded in the form of a word knowledge base (raw or digitized) or in the form of a statistical model designed from a large corpus of words.
The mode of knowledge storage will influence the way in which the user’s request is processed. Thus, using the standard architecture of chatbots described above, the preprocessing applied to the request will usually be more important in the case of a model. Detecting the user’s intention typically includes the entire interaction and not just the last request.
The most marked difference in processing between the two storage modes, however, is the way in which the response is generated. In the case of a word knowledge base, the most appropriate response is chosen from a set of pre-existing possible responses. In the case of a statistical model, the response is generated dynamically at the time of the request. It should be noted that the response offered by a chatbot with a word knowledge base is deterministic: the same response will be offered every time for the same request. This characteristic makes this type of chatbot more suitable for a closed domain where the accuracy of the response to the question asked is usually the most important evaluation criterion.
However, this type of chatbot suffers from two main limitations. On the one hand, this type of chatbot cannot respond to a request that is not part of the knowledge base. On the other hand, its ability to display human traits can be altered by this deterministic aspect. For a chatbot powered by a statistical model, the reality is quite different. The statistical model allows for a response to any type of question, but it may vary from one request to another. This type of chatbot is usually more appropriate in an open domain where creativity predominates over factual aspects.
ChatGPT is currently the muse of chatbots powered by a statistical model. Version 4 has just been released, 4 months after the previous version (v3.5), but it is not widely known because it is only available through a paid subscription. In the following, we will mainly discuss version 3.5, which has been publicly available since November 2022. This model has 175 billion parameters, more than 100 times more than its previous version (v2). It was created by the company OpenAI, which was founded in 2015 as a non-profit association with the aim of helping humanity through artificial intelligence. Since 2019, the purpose of this company has changed and it also includes conventional commercial activities.
ChatGPT v3.5 works through text exchanges and it is accessible to everyone for a wide range of requests such as answering closed or open-ended questions (e.g., what to do if you forgot to buy a Valentine’s Day gift?), assisting with text or code writing (https://chat.openai.com/chat). In terms of anthropomorphic capabilities, it takes into account the context of the request, that is, the entire interaction with the user. It is therefore possible to further specify the request if the current response given by ChatGPT is not considered satisfactory by the user. It is also trained to decline requests that are deemed inappropriate from a legal or ethical point of view. Finally, one can ask ChatGPT to formulate its response in a given style (e.g.: using a dialect, in the manner of a schoolmaster), but it does not adapt the response to its interlocutor on its own initiative.
Based on our tests, our feeling is that, like the human brain, two hemispheres struggle behind the answers provided by ChatGPT: a left hemisphere dedicated to the search for truth and a right hemisphere dedicated to the search for creativity. Depending on the type of request, one of the two hemispheres is predominant, or both intervene. In the case where the request relates to problem solving, code creation or testing, text reworking, the left hemisphere is mainly activated and the response is generally of good quality, but it is not infallible. For example, it is best to avoid asking it problems containing language subtleties. For other requests involving the creation of text based on user input (e.g.: a story with crocodiles and Vikings), the right hemisphere is more dominant. The result obtained is generally also interesting, but there may be areas for improvement such as a low level of content, repetitions or incomplete sentences. Finally, in the case of factual questions, both hemispheres of ChatGPT are involved: as long as the request passes the filter of questions deemed inappropriate, it always gives an answer. Like a good speaker, if it knows the answer, it responds appropriately, otherwise it invents a plausible answer. It can, for instance, discourse on the differences between chicken eggs and cow eggs.
From our point of view, except for the last discussed use case, ChatGPT provides useful support to its users, provided they have the necessary expertise to validate and improve the response as needed. In a professional context, this tool can offer a significant productivity gain for various professions, particularly those related to creating textual content and computer programs. However, this tool is not without societal risks. The education sector could be particularly affected by this tool: how can we ensure that the author of an assignment or any other report written outside the school walls is indeed the learner and not ChatGPT? More generally, we may now question the real author of a written work. Furthermore, due to its ability to handle large volumes of requests, this chatbot could contribute not only to a depletion of the content of information available on the web but also to mass disinformation. Finally, despite being trained to filter out unwanted requests, ChatGPT is likely to make the achievement of malicious actions requiring a certain level of expertise accessible to a wider audience, such as developing hacking software.
Compared to version 3.5, the new ChatGPT version 4 reportedly addresses some of the identified weaknesses. It is said to be 82% less likely to respond to unwanted requests and 40% more likely to correctly answer factual questions [3]. In addition to these improvements, the most significant contribution of this version is that ChatGPT can now leverage images submitted by the user.
In recent years, CETIC has developed expertise in designing chatbots, following collaborations with Walloon companies eager to accelerate their digital transformation. Currently, our research interests in this area mainly concern the design of chatbots capable of translating requests from novice users into technical specifications for a specific business need. As an illustrative example, we are investigating the use of a chatbot to design dynamic dashboards to track the evolution of time series collected in our TSorage tool. On this same research line, we are also collaborating with the University of Namur as part of a doctoral thesis focusing more broadly on the development of dynamic dashboards based on interaction between a chatbot and a business user.