
The World Wide Web can be considered an infinite source of information for both individuals and organizations. Yet, if the standard language of publication on the Web (HTML) is well suited to human reading and navigating in interactive sessions, its poor semantics makes it difficult for computers to process and use embedded data in a smart and automated way. To tackle this problem, the CETIC is prototyping Web data extraction technologies, i.e., software components aiming at clustering and interpreting Web documents.
Date: 19 October 2004
About project
Composed of Web sites interconnected by hyperlinks, the World Wide Web can be seen as a huge but chaotic source of information. Encoded in a semantically poor format (HTML), Web data are indeed well suited to human reading in interactive sessions but cannot easily be processed automatically by software agents. The problem lies in the mixture of data and layout instructions in HTML sources and their lack of semantic information. In parallel, with the development of commercial B2B Web applications, the need for extracting Web data towards a computable format substantially grew in recent years.
Retrozilla, a tool developed by the CETIC, is dedicated to the clustering and the semantic analysis of Web sources. It allows to build an intermediate layer between HTML-embedded data and external applications, providing the latter with an easier access to relevant information scattered through Web sources.
Content syndication
On the Web, data related to an application domain are scattered through various sites or even various pages within a site. Consequently, getting a sound overview of specific information is not an easy task (for instance, consulting the price of a specific item at various resellers). By providing an easy access to similar information from various Web sources, Retrozilla can help you to build your own dashboards.
Smart search engines
Most present search engines carry out a syntactic analysis of Web content. Indeed, each word of a page is indexed on a context-free basis. As a result, simple queries can lead to irrelevant and/or heterogeneous results (for instance a query on the word "jaguar" will give references to sites dealing with cars, operating systems, wildlife foundations, online bookshops or movie databases). By giving semantic information to Web data, Retrozilla can contribute to the development of smarter search engines.
Competitive intelligence tracking
Some types of data are intrinsically evolutive (prices, customer comments) and of very high importance to some actors of a specific domain. For instance, cell phones resellers are interested in keeping an eye on the prices, special offers and new products at their competitors’. Similarly, book editors will probably be interested in getting new comments on their books by readers as soon as they are published at Amazon.com. By allowing you to choose which kinds of information are relevant to you, Retrozilla can help you to monitor them and to be aware of their evolution.
Web sites evolution
Today many Web sites are still (semi-)static, i.e. their data are directly encoded in HTML pages rather than loaded from an underlying database through scripts. Most often, such sites follow a typical pattern of evolution. In the beginning, only a few pages are published but sites grow constantly until they become unmanageable. At that time project leaders decide to develop a dynamic site, but they realize that it is a costly operation (ressources needed, risk of data loss). Retrozilla allows to collect your data with minimal human intervention. They can then be migrated towards a WCMS or a DBMS.
Developed by the CETIC as a plugin for the (open-source) Firefox Web browser, Retrozilla is a toolbox enabling fast and accurate data extraction from the Web. It includes a Clustering Engine (grouping of Web pages according to categories) and a Semantic Browser (user-oriented analysis of information inside web pages).

The Clustering Engine identifies categories of web pages amongst all the documents composing a Web site. It relies on similarities in the syntactical structure and in the content of Web pages to group them into so-called page clusters. For instance, all the pages describing books in the Amazon web site are automatically classified in a common cluster by the Clustering Engine.
With Retrozilla, it is very easy to have access to and use any information displayed in pages of a given cluster, using the Semantic Browser. The latter is actually a Web browser allowing to select and describe any relevant piece of information one would want to access. An access path is then automatically computed and used by any external application (dashboard, search engine,...) to extract embedded data from source HTML documents.
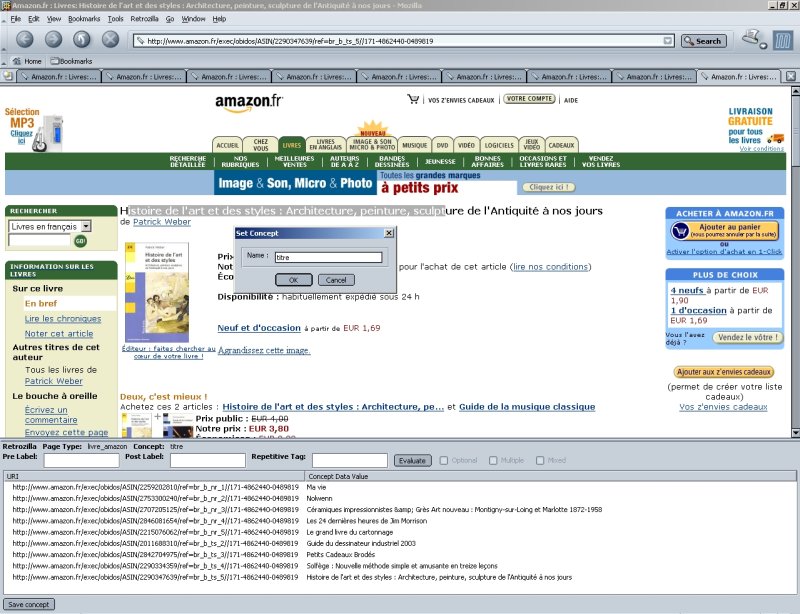
The main advantages of the Semantic Browser are listed below: