
The search engine market is mainly dominated by three big players but these strong giants also have weaknesses. In many cases, a solution of personalized research can be more efficient that the generalist search engines approach. Thanks to multiple research projects, CETIC is developing a strong expertise in search engine technologies.
Dedicated search engines are taking advantage of research undertaken in labs and universities, best-of-breed software development (open source or proprietary), and forward-thinking concepts such as semantic web, or the inclusion of the deep web into the picture.
The comparative advantage with a generalist search engine lies in :
Strong leaders...
The search engine market is mainly dominated by three big players : Google, Yahoo and MSN. Their cumulated market shares reach more than 90 percent and they profit from a strong and recognized reputation (the three are in the Top 100 Interbrand Brand Ranking). They rapidly grew by word of mouth due to their innovative technology.
Google, for example, invented the page rank (the popularity of a page is measured from the number of links pointing to it), ran with a farm of cheaper computers (rather than big and expensive centralized computers) and had a very simple interface (lighter than traditional portal as the leader Altavista). Moreover, Google has always been relying on proven business model, based on contextual advertising (Adwords).
...with weaknesses
Often victims of their success, these leaders also hide weaknesses.
Google proposes a lot of tools related to search but with a poor integration; MSN Search is trying a stronger integration but is still young, suffers from a spam-sensitive algorithm and a low number of sources (news and images). As for Yahoo, it has to manage the heritage of three different technologies.
In general, users hate changes, so the innovation must be less disrupting as possible. The companies of search engine are dependent on a mass-market which handicaps them in the satisfaction of particular needs.
The quantity of information available on the Internet is enormous (several billion documents) and growing exponentially. In that context, search engines are crucial elements to optimally exploit this gigantic database. They allow to find documents related to a specific (set of) term(s) and consist in a toolbox realizing the following operations:
Crawling: collecting documents by following links
Robots, called spiders, find documents on the Web by recursively following links contained in these documents.
As no search engine is able to crawl the whole web in one day (this process generally takes several weeks), each system thus adopts a specific strategy. A crawler is usually parametrized by a level of deepness (number of links to follow from the home page) and freshness (time between two crawling steps - freshness depends on the update frequency of the site).
In order to optimize bandwidth use, spiders can work in a distributed way by sharing their fetchlist (i.e. list of URLs to fetch) with other agents.
Analysing: transforming documents into tokens
Most of the fetched documents are HTML pages but some of them can be in heterogeneous formats such PDF or Word. Analysing transforms any document into a sequence of machine-processable textual tokens.
The analyser should be finely tuned as it is a crucial part of the search engine. Indeed, it directly determines the content of the future index by:
Indexing: storing and making documents searchable
During the indexation step, the tokens extracted from documents are stored in a data structure that allows fast random access. The index structure is identical to the structure used in a book index: an index entry gives, for one word, the (list of) document(s) where the word appears.
Searching: displaying the best results from keywords
By consulting and computing the index, searching aims at providing the best documents from a (set of) keyword(s). The fished out documents are classified according to a decreasing order of relevance. Index of popularity is mostly taken to order the results, but many other criterions can be used as document coherence, users votes, semantic document value...
Originally, pioneering popular search engines, such as Altavista or Lycos, were characterized by common features:
a graphical relative sobriety:
One of the success factor of Google comes from its simplicity of use. Indeed, the Google’s home page merely consists in an ordinary logo, one textbox and one click-button. How could it be simpler ?
a simple but efficient underlying technique:
The index is build from a syntactical analysis of documents. When an user searches information about "Europe", no distinction can be made between the continent and the famous 80’s rock band.
Some shy evolutions appeared in theses fields.
Exalead introduced basic semantic search. It extends search to close terms and proposes related searches and related categories. With this technology, Exalead will be often able to understand that, when you search for ’windows gates’, you can search after Microsoft software or doors for a house, for exemple !
The Kartoo French company introduced fresh idea. Kartoo is a cartographic search engine. Far from the initial sober GUIs, it displays its search results in the form of clickable spheres tied together by semantic links. The overall constitute a flashy presentation including navigable and animated results.
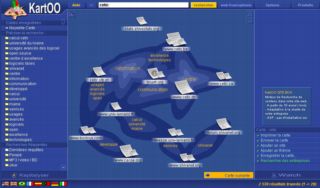
But these innovations did not shake the leaders. Today, as techniques evolve and concurrence is harsh, search engines try to distinguish from each other. The recent trends in search engines are:
personalization:
Results returned from identical query terms depend on the user profile (age, hobbies, location,...). Some techniques of geolocalisation are today commonly used to inform users on the closest shops or pubs.
Mirago developed geolocalisation algorithm and tested a business model based on affiliation. It provides XML feeds with search results including sponsored results.
Provided that the user registers and reveals some information about him, other systems undertake to provide the more pertinent results according to the user’s profile. Users sharing the same centre of interest (communities) can also collaborate to find the best documents from a query term. These solutions rely on human intelligence rather than computer analysis to find information on the web.
Fooxx introduced the community search. Once login, you can manage your bookmarks. Bookmarks are classified in categories and each user belong to communities. The bookmarking activity influences the ranking of a page : it is the principle of personal rank. Kartoo also released Ujiko, which has a rudimentary system of bookmarks (rejected / approved with score).
extra functionalities in search:
Much more than providing a result list from a query term, major actors offer today some helpful extra functionalities in their search interface. Google has recently extended the types of its indexed media by allowing to search for news or videos.
As the numbers of results returned for a query is often relatively large, Clusty uses "clustering" to gather them in semantic categories.
bridge towards the externals:
Another noticeable trend in search technologies is the opening towards the external world. In that context, Google and Yahoo! gives a restricted access to their system by external applications via an API or XML feed.
Because web search should not become a monopoly, alternative open-source solutions (Nutch, ASPSeek) are now emerging. By making public their inner (ranking) algorithms, they ensure transparency in their search results (these are too often biased by commercial interests in proprietary systems).
integrated tool suite:
Because search is everywhere, big players integrate their search capabilities with other web tools such as web mail, instant messenger, shopping search engine or online music players.