
Les métadonnées sont utilisées depuis des années afin de faciliter l’exploitation des métriques des data centers (taux d’utilisation de la RAM, températures des CPU, etc.). Il s’agit d’associer à chaque capteur, voire à chaque mesure, un ensemble de propriétés qui donnent un sens humainement compréhensible à la mesure. Malgré les similitudes existant entre les data centers et les sites de production, de telles métadonnées sont encore très peu utilisées dans un contexte industriel.
Cet article présente cinq avantages que vous pourriez tirer de l’adoption par votre entreprise d’un outil gérant ces métadonnées.
Date: 14 septembre 2020
Secteurs
A propos du projet
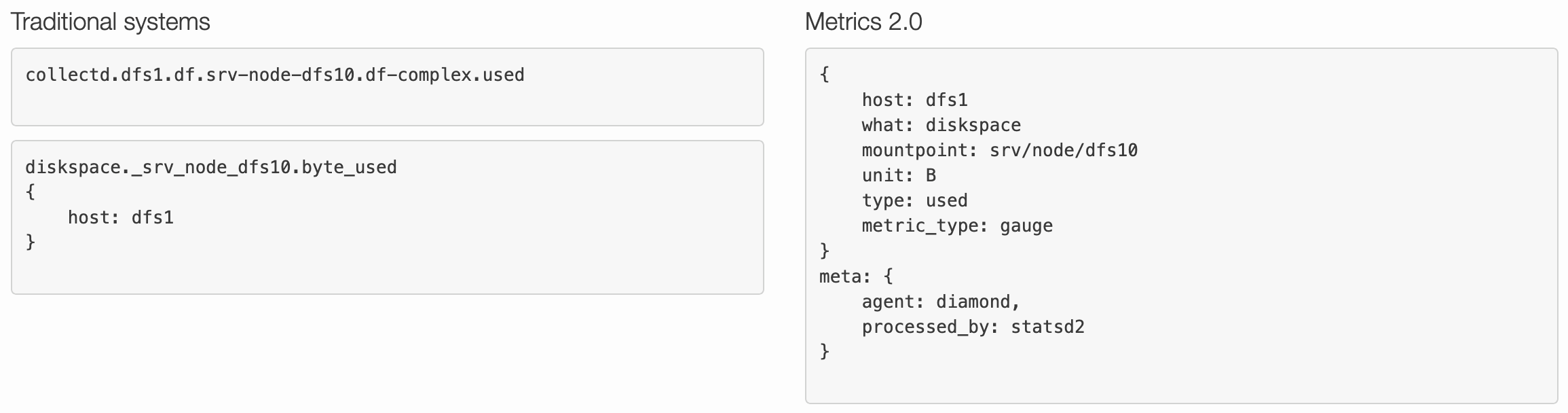
L’approche la plus commune dans l’industrie pour gérer les données provenant d’un réseau de capteurs consiste à associer à chaque capteur un nom unique. Ce nom est déterminé à partir d’une nomenclature décidée par l’entreprise, de sorte qu’un utilisateur connaissant la nomenclature ayant cours peut déduire, sur base de son nom, le sens à donner à un capteur (son emplacement, la nature de ce qu’il mesure, etc.).
Cette approche présente plusieurs limitations, dont l’importance augmente au fur et à mesure que le réseau de capteurs s’étend et qu’il est de plus en plus difficile pour l’utilisateur de connaître « personnellement » les capteurs nécessaires à la gestion quotidienne de l’usine. Une autre approche, permettant le passage à l’échelle de l’exploitation des capteurs, s’avère alors intéressante.
Metrics 2.0 est un ensemble de conventions, de standards et de concepts qui proposent une telle approche. Au cœur de sa proposition, on trouve l’idée qu’à chaque observation doit être associé un ensemble de paires clef-valeur qui caractérisent l’observation. Collectivement, ces paires, parfois aussi appelées tags, constituent les métadonnées d’une observation.
Les clefs des tags doivent idéalement représenter un ensemble de concepts (ou dimensions) orthogonaux, tels que le nom du fabricant du capteur, la nature de la mesure réalisée, la fiabilité de la mesure, etc. Les valeurs associées à ces clefs permettent de qualifier l’observation du point de vue de la dimension représentée. Par l’association des métadonnées adéquates à une mesure, on pourra ainsi déterminer que celle-ci provient d’un capteur produit par Siemens, qu’il s’agit d’une mesure de température et que tout indique qu’elle est de bonne qualité.
Avec l’approche Metrics 2.0, le nom du capteur n’est plus porteur de sens, puisque ce sont les métadonnées qui sont utilisées aussi bien par l’humain que par la machine pour décrire la mesure. Il peut même être complètement ignoré par l’utilisateur.
Comme indiqué en introduction, une approche basée sur les métadonnées facilite la gestion systématique de réseaux de capteurs dont le nombre d’éléments, progrès et besoins obligent, ne cesse d’augmenter au cours du temps. Dans le reste de cet article, nous abordons cinq avantages concrets dont vous, exploitant de données industrielles, pourriez tirer de cette approche.
1. Des données qui se décrivent elles-mêmes
Un des avantages les plus directs de l’utilisation de métadonnées est l’expression explicite et intégrée de la sémantique associée aux mesures. Pour l’utilisateur, il n’est plus nécessaire de déduire les caractéristiques d’un capteur à partir d’une nomenclature arbitraire. Le recours à une fiche descriptive associée à un capteur devient inutile. Des éléments d’information peuvent être attachés à chaque mesure, facilitant l’enrichissement sémantique des données.
2. Filtrage et agrégation systématique
Ce caractère autodescriptif des données bénéficie aussi aux systèmes informatiques, tels que les applications de visualisation (dashboarding, monitoring, etc.) qui peuvent générer automatiquement des vues agrégeant et ventilant les données. Les applications peuvent tirer profit de l’enrichissement sémantique apporté par les métadonnées pour améliorer la compréhensibilité de ces vues. Par exemple, les titres des figures et des axes ont davantage de sens pour l’utilisateur, puisqu’ils proviennent directement de vos métadonnées !
Couleurs, formes et tailles peuvent être utilisées automatiquement afin de mettre en évidence les données de natures similaires, ou au contraire pour mettre en exergue leurs différences. Il en résulte un gain de temps pour l’utilisateur qui doit moins fréquemment « retravailler » un graphique afin de le rendre compréhensible.
Les applications peuvent également proposer automatiquement des menus pour filtrer le contenu à afficher et pour naviguer dans les données à explorer (lors d’un drill down, par exemple).
3. Une plus grande expressivité lors de l’interrogation des données
Selon l’approche traditionnelle, la sélection d’un capteur se base sur le nom de celui-ci. L’utilisateur dispose typiquement d’une barre de recherche permettant de saisir (une partie) du nom recherché. Les outils proposent généralement une recherche insensible à la casse et l’omission des caractères non alphanumériques. Parfois, une forme plus ou moins complexe d’expression régulière peut être utilisée, ce qui apporte plus d’expressivité aux requêtes (par exemple en utilisant des jokers), mais implique que l’utilisateur maîtrise à la fois le langage d’expression régulière et la nomenclature utilisée.
Lorsque les mesures sont organisées sur base de métadonnées, l’utilisateur peut exprimer une requête comme une combinaison d’inclusions et d’exclusions de valeurs pour certaines dimensions. Filtrer ou ventiler les résultats sur base de plusieurs dimensions ne nécessite plus d’écrire d’expressions régulières complexes. L’outil peut assister l’utilisateur en lui suggérant des dimensions qu’il serait pertinent d’intégrer dans une requête, et en lui indiquant les valeurs existantes pour ces dimensions.
4. Une gestion facilitée de l’uniformisation
Les solutions d’historisation sont exploitées par différents groupes d’utilisateurs. Lorsque l’entreprise est multinationale, ces utilisateurs peuvent avoir des langues maternelles différentes, et le recours à une langue unique (l’anglais, par exemple) peut s’avérer contraignant pour certains d’entre eux. De plus, les utilisateurs partageant la même langue peuvent appartenir à des métiers différents, chaque métier ayant au cours du temps développé son propre vocabulaire. Afin de réduire les risques de glissement sémantique et les problèmes de compréhension du sens de la donnée considérée, il est nécessaire de prendre en compte les spécificités de chaque groupe d’utilisateurs.
Avec les logiciels actuels, la solution typique à cette problématique consiste à associer à chaque capteur une « description » traduite selon les besoins de chaque groupe d’utilisateurs. Lorsque l’entreprise dispose de k capteurs et de n groupes d’utilisateurs, cela revient à gérer la rédaction de k*n descriptions. Une attention particulière doit être apportée afin d’assurer la cohérence du vocabulaire utilisé, de sorte qu’un concept soit toujours exprimé et traduit de la même manière.
Avec une organisation basée sur les métadonnées, un dictionnaire doit être proposé pour les d dimensions et les v valeurs de dimension référencées par le système, soit (d+v)*n mots à rédiger. Lorsque les dimensions sont orthogonales, (d+v) est typiquement bien plus petit que k. De plus, dans la mesure où chaque terme n’est traduit qu’une seule fois, la cohérence du vocabulaire utilisé est assurée par construction.
5. Une organisation des données plus flexible

Dans les outils traditionnels, les capteurs sont organisés de manière hiérarchique, selon une organisation déterminée à l’avance. Le plus souvent, la nomenclature des capteurs tente de correspondre à cette organisation. Sur le terrain, les utilisateurs doivent donc naviguer dans un arbre dont la structure est rigide, et donc plus ou moins adaptée et pertinente en fonction du contexte d’utilisation. En particulier, toute manipulation de capteurs placés sur des branches éloignées les unes des autres s’avère laborieuse.

Avec un système basé sur des métadonnées, l’utilisateur a la capacité de supprimer les dimensions qui ne l’intéressent pas, et d’indiquer à l’outil l’ordre dans lequel les dimensions restantes doivent être utilisées afin de créer dynamiquement un arbre représentant les capteurs.
Une approche plus transversale peut également être adoptée, en proposant à l’utilisateur un système de filtrage similaire à celui proposé par de nombreuses boutiques en ligne : un système de cases à cocher permet alors de choisir les valeurs acceptables pour certaines des dimensions disponibles.
La plupart des outils de surveillance et d’alerte « nouvelle génération » (à partir du début des années 2010, pour situer les choses) ont adopté un système de métadonnée pour la gestion et l’interrogation de séries chronologiques. Malheureusement, le marché semble principalement s’orienter sur les données issues d’infrastructures informatiques. Avant de considérer l’adoption d’un tel outil, il est donc nécessaire de déterminer son adéquation avec un usage industriel.
Le projet OpenMetrics, initié par Prometheus, regroupe un ensemble de bases de données de séries chronologiques qui, non seulement supportent le concept de métadonnées, mais proposent également une manière unique de les représente. Cela favorise l’émergence d’un standard ouvert pour la transmission de mesures. En plus de Prometheus, OpenTSDB, Google Cloud Platform, InfluxDB, DataDog et TSorage supportent le format OpenMetrics.
Les outils de surveillance et d’alerte pour infrastructures réseau existent depuis des décennies. Devant l’augmentation extrêmement rapide du nombre de capteurs qu’un tel outil doit prendre en charge (due notamment à la généralisation des techniques de virtualisation), des démarches sont entreprises depuis quelques années pour continuer à fournir aux utilisateurs des solutions pertinentes et humainement utilisables. Une approche basée sur les métadonnées s’inscrit dans cette optique en permettant l’enrichissement sémantique des données traitées à grande échelle.
La généralisation de l’IIoT, et plus globalement la modernisation des techniques nécessaires à la bonne marche d’une usine, amène inévitablement l’industrie à une situation similaire à celle qu’a connue le secteur IT, avec une croissance sensible du marché du capteur industriel dans la décennie à venir.
Ainsi qu’exposé dans cet article, une approche basée sur les métadonnées offre plusieurs avantages concrets lorsqu’il s’agit d’extraire de la valeur des mesures issues de capteurs industriels. À n’en pas douter, celui ou celle qui saura exploiter ces avantages (par le développement de nouveaux services, par exemple) aura définitivement fait un pas de plus vers l’industrie de demain.