Dans le projet TRICARE, le CETIC a développé une application qui s’alimente d’un flux de données provenant des capteurs installés dans une habitation et qui transforme ce flux d’origine en plusieurs flux de données par des processus appelés reconnaisseurs, selon des règles de reconnaissance préétablies. L’objectif de cet article est de présenter les bases de ces processus de transformation des flux de données et leur utilisation concrète dans TRICARE.
Dans le monde hyper connecté d’aujourd’hui, les données sont générées et interprétées à une grande vitesse. Des nouveaux genres d’applications informatiques tirent profit de ce volume d’information grandissante, comme le montre l’essor actuel du Big Data et la dernière vague de « l’intelligence artificielle ».
Les données peuvent être générées à partir de différentes sources de données et alimenter les applications/processus d’une manière continue. Certaines applications demandent un traitement rapide, sinon en temps réel, de ces données, qui à son tour peut devenir une nouvelle source de données pour une autre application/processus.
Dans le cadre du projet TRICARE, le CETIC a développé une application qui s’alimente d’un flux de données provenant des capteurs installés dans une habitation et qui transforme ce flux d’origine en plusieurs flux de données par des processus appelés reconnaisseurs, selon des règles de reconnaissance préétablies. L’objectif de cet article est de présenter les bases de ces processus de transformation des flux de données et leur utilisation concrète dans TRICARE.
Dans un processus reconnaisseur, un ensemble de règles permet d’établir si une donnée (alimentant le flux transformé) peut être construite à partir d’un ensemble de données du flux d’origine. Notons que les données du flux sont « consommées » selon l’ordre dans lequel elles sont générées. Supposons que les données d’un flux peuvent être catégorisées et qu’une donnée d’un flux n’appartient qu’à une seule catégorie. Les règles de reconnaissance mettent donc en relation la catégorie de la donnée du flux de sortie à partir des données du flux d’entrée, appartenant à une catégorie et respectant des conditions sur ses informations internes, dans une « zone tampon » du flux d’entrée.
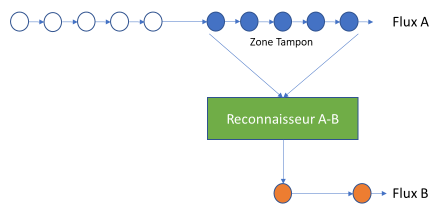
Le type de règle le plus simple à définir est la règle de correspondance séquentielle : à une séquence de données d’une catégorie A dans la zone tampon correspondra une donnée de la catégorie B dans le flux de sortie. Par exemple, quand un capteur de présence dans une pièce est activé par quelqu’un qui entre dans la pièce, cela va générer plusieurs données du capteur dans le flux d’entrée. Avec une règle, une donnée de sortie spécifiant la « présence dans la pièce » peut être générée dans le flux de sortie. Des informations peuvent enrichir cette donnée, telles que le temps de début et fin et le nombre de données d’entrée associées.
Un autre type de règle est celui d’absence : si dans la zone tampon il n’y a aucune instance de donnée d’une catégorie A, une donnée de la catégorie B peut être générée en sortie, au moment où il y a un changement ou une vidange de la zone tampon.
Un deuxième type de règle, le nombre d’instances, relie un nombre fixe de données du flux d’entrée à la donnée de sortie. Par exemple, supposons qu’une alerte doit être donnée quand une activité anormale a dépassé un certain seuil. Si après avoir exploré la « zone tampon » du flux d’entrée on retrouve un nombre d’instances de l’activité anormale supérieur au seuil, une donnée d’alerte peut être générée en sortie.
Le type de règle le plus général est la règle multi-catégorie : si dans la zone tampon on retrouve des données appartenant à des catégories A1, …, An, une donnée de la catégorie B peut être généré dans le flux de sortie. Si la zone tampon est vide, il serait possible de générer un donnée « incomplète », ce qui peut être utile dans certains contextes pour savoir si une tâche a pu commencer mais pas se terminer.
Le contenu de la zone tampon évolue selon l’application et la manière dont on active les processus reconnaisseurs. Il peut s’agir, par exemple, des données des dernières 24 heures, ou de la dernière semaine, mais aussi de tout l’historique des données.
L’objectif du projet TRICARE est de développer une application pour le suivi des personnes âgées à leur domicile, d’une manière non intrusive, à partir des informations des capteurs de présence intégrés dans les systèmes d’alarme construit par le partenaire industriel, AnB-Rimex.
L’application développée par le CETIC comporte deux composants principaux, TRANSCARE et MADLE.
TRANSCARE est le composant qui traduit les données brutes des capteurs installés dans l’habitation dans le flux de données d’entrée (appelés évènements dans le contexte de TRICARE), représentant les actions. Il est donc le premier processus reconnaisseur de l’application TRICARE, mais le seul qui dépend d’un format extérieur.
MADLE est le composant qui réalise le monitoring des personnes âgées à partir de différents flux transformés par des processus reconnaisseurs. Les reconnaisseurs font en sorte que les flux des évènements soient enchaînés mais chacun est activé de manière indépendante.
![]()
Voici les différents types d’évènements traités par le composant MADLE :
Les règles de reconnaissance des évènements d’action, ADL, anomalie et alerte sont stockées dans une base de données à l’intérieur de MADLE.
Le projet TRICARE est arrivé à sa fin avec l’étape du pilote d’AnB-Rimex qui déploiera les composants TRANSCARE et MADLE intégrés à leurs systèmes d’alarme pour un ensemble d’utilisateurs sélectionnés. Du coté du CETIC, il sera possible d’utiliser ces techniques de transformation de flux de données dans d’autres contextes, tels que la gestion des bâtiments. Une application des techniques de Machine Learning sur les flux de données pour rendre les règles de reconnaissance adaptables est également envisageable.
Pour plus d’information n’hésiter pas à prendre contact avec :
Gustavo Ospina
Lotfi Guedria
