
Le Laboratoire de Biologie Clinique de la Clinique Saint-Luc Bouge, en collaboration avec l’UZ Gent, a élaboré un modèle de prédiction de la probabilité d’une infection urinaire. Le CETIC est intervenu pour opérationnaliser ce modèle (MLOPS) directement au moment de l’analyse des échantillons. Cette prédiction permet aux médecins de prendre des décisions plus rapidement
Cette approche ne remplace pas l’analyse traditionnelle, qui prend 48 à 72 heures, mais la complète en offrant une première information rapide et fiable. Le projet a ainsi créé un double flux : l’un instantané et prédictif, l’autre classique et de référence, pour une meilleure prise en charge des patients.
Date: 19 août 2025
Expertises
Domaine
A propos du projet
Auteurs
Le projet déployé au sein du Laboratoire de Biologie Clinique de la Clinique Saint-Luc Bouge a permis d’introduire un nouveau flux parallèle de diagnostic. Lorsqu’un échantillon d’urine arrive, il est soumis à une analyse rapide qui extrait immédiatement un ensemble de caractéristiques pertinentes. Ces données sont ensuite validées, enrichies avec quelques données démographiques concernant le patient, et transmises à un modèle de prédiction basé sur le machine learning. En quelques secondes, le laboratoire est capable de proposer une réponse prédictive sur la probabilité d’une infection urinaire, directement intégrée dans le LIMS et accessible au médecin.
En parallèle, l’échantillon suit toujours le circuit traditionnel de bactériologie (culture et antibiogramme), dont les résultats ne sont disponibles qu’après 48 à 72 heures. Ce double flux offre au clinicien un avantage décisif : disposer rapidement d’une première information, tout en conservant la confirmation de référence fournie par l’analyse classique.
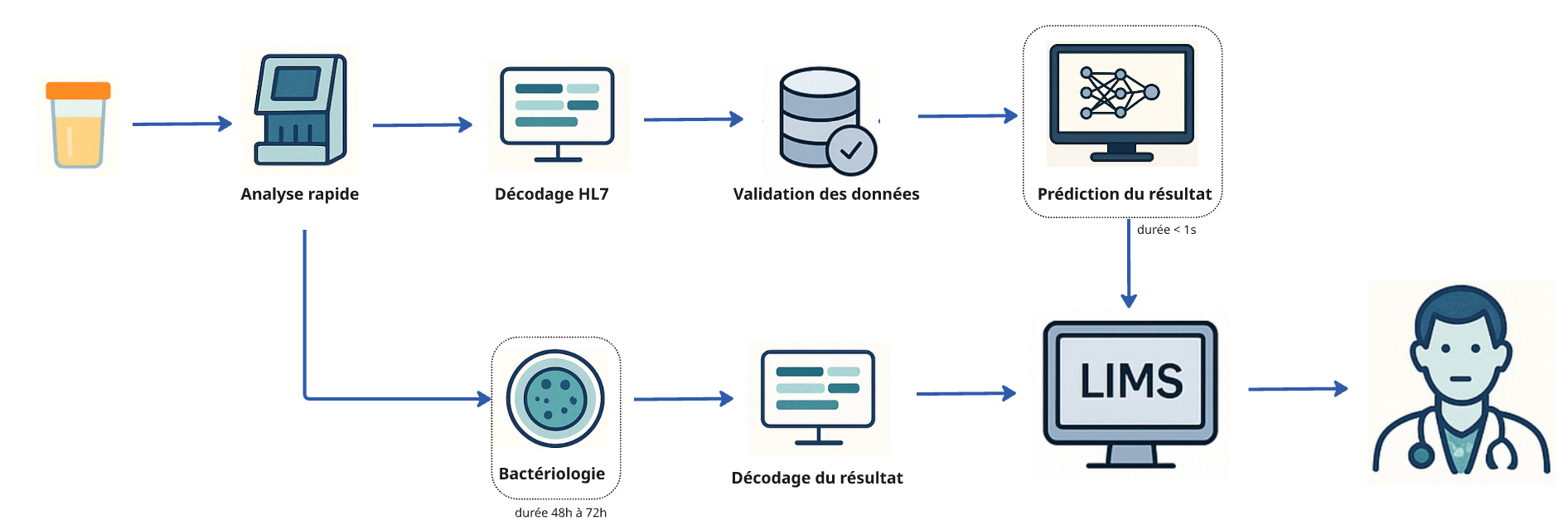
Nous avons conçu une solution complète, du traitement initial des données brutes à la restitution finale dans le LIMS. L’approche repose sur un pipeline MLOps orchestré qui gère la réception des résultats de l’analyse rapide, leur validation, leur transformation au bon format, puis l’appel au modèle prédictif. Les résultats sont ensuite stockés, validés et réinjectés dans le système d’information du laboratoire au format HL7v2.
L’objectif n’était pas de remplacer la bactériologie, mais d’apporter un complément rapide et fiable au médecin afin d’orienter ses décisions dès la réception de l’échantillon.
Au cœur de la solution se trouve un pipeline en Python orchestré par Apache Airflow. Ce choix garantit robustesse et flexibilité :
Chaque composant critique, y compris le module de traitement de données dans Airflow, a été conteneurisé afin d’assurer portabilité, reproductibilité et déploiement homogène dans différents environnements.
Toutes les données transitant par le pipeline sont stockées et historisées afin de permettre des audits, des réanalyses ou des comparaisons ultérieures. Cette historisation assure la traçabilité complète des résultats et contribue à la conformité réglementaire dans un contexte hospitalier sensible.
Un défi majeur concernait le fait que l’analyseur peut envoyer les résultats rapides en plusieurs fragments HL7 complémentaires. Nous avons mis en place une logique de réconciliation automatique : le pipeline regroupe les messages reçus, reconstitue l’ensemble des caractéristiques attendues, et ne poursuit le traitement qu’une fois les données jugées complètes et cohérentes.
Une étape cruciale du pipeline consiste à valider la qualité des données reçues. Les valeurs aberrantes, manquantes ou incohérentes sont détectées, et le message HL7 initial est rejeté ou corrigé selon des règles préétablies. Les données validées sont ensuite structurées dans un format standardisé qui correspond aux attentes du modèle de prédiction.
Le modèle de prédiction a été développé, versionné et packagé avec MLflow. L’image Docker générée via MLflow est déployée sur l’infrastructure du laboratoire, garantissant la reproductibilité des résultats et la possibilité de rollback en cas de problème.
La version actuelle du modèle est stockée dans une instance MLflow, ce qui ouvre de nouvelles perspectives : suivi de performances, réentraînement si nécessaire, traçabilité des expériences de réentraînement, et déploiement simplifié d’une nouvelle version venant remplacer l’existante.
Une fois la prédiction produite, elle est validée et stockée pour traçabilité, puis reformattée en message HL7v2 avant d’être renvoyée dans le LIMS. Ainsi, pour le médecin, l’expérience est totalement transparente : il reçoit le résultat prédictif dans le même environnement que ses autres résultats de laboratoire, avec un délai de quelques minutes seulement.
Cette mise en place démontre concrètement comment les approches MLOps peuvent transformer le quotidien hospitalier, en combinant rapidité, fiabilité et intégration avec les outils existants. Elle ouvre la voie à d’autres applications similaires, où les modèles de machine learning viennent enrichir, sans remplacer, les analyses traditionnelles, au service du patient et du clinicien.