Cet article analyse, à l’aide d’un modèle prédictif entrainé sur des données réelles, les liens identifiés entre le profil et l’historique d’un groupe de consommateurs (communauté énergétique d’autoconsommation collective) sur la prévision de sa consommation électrique à court terme, afin de déterminer les données nécessaires à la mise en place efficace d’une telle communauté.
Date: 3 mai 2020
Domaine
Thème d'innovation
A propos du projet
Auteurs
Dans le cadre du projet GAC, le CETIC analyse l’impact du profil d’une communauté énergétique sur la prévisibilité de sa consommation électrique. Une communauté énergétique est un groupe de consommateurs/prosumers qui s’organisent de manière à maximiser l’autoconsommation de l’énergie produite localement, afin de réduire la charge du réseau électrique, optimiser l’utilisation des énergies vertes décentralisées, et réduire le coût de l’électricité. En des termes plus simples, le but est de consommer intelligemment, comme par exemple un participant démarre sa machine à laver lorsque son voisin est absent de chez lui mais que ses panneaux solaires produisent de l’électricité. Ceci permet de limiter le transport de l’électricité sur un réseau déjà surchargé, ce qui limitera les pertes sur le réseau et les coûts d’infrastructure. Cela permettrait également, après mise en place d’un cadre légal, d’acheter directement son énergie à un voisin à un tarif intéressant.
La Belgique est un des pays où la production résidentielle d’énergie - principalement photovoltaïque - a le plus augmenté ces dernières années, rendant cette opportunité particulièrement concrète dans notre région. Ainsi, la Belgique, et plus généralement l’Europe, sont en train de mettre en place des plans pour une gestion réglementée de ces communautés énergétiques, permettant d’espérer voir apparaître de nouveaux acteurs modernes de l’énergie : des "gestionnaires agréés d’autoconsommation collective".
La mise en oeuvre efficace d’un tel système nécessite néanmoins de pouvoir prévoir la production et la consommation locales à venir. Or la qualité de cette prévision dépend des différentes caractéristiques de la communauté énergétique, qui la rendent plus ou moins prévisible. Par exemple, plus le nombre de consommateurs inscrits dans la communauté est grand, plus la consommation globale (agrégée) sera facile à prédire, car elle sera moins aléatoire : elle dépendra du comportement global d’un grand nombre d’individus, et non du comportement plus aléatoire d’un seul ménage. En outre, les modèles prédictifs ont besoin d’un grand nombre de données historiques pour pouvoir modéliser, i.e. apprendre, le comportement de la communauté. Ainsi, plus l’historique de données est long, plus le modèle sera performant.
Afin de pouvoir évaluer la faisabilité de mise en place d’une communauté énergétique, nous avons donc étudié l’impact de différents facteurs sur cette prévisibilité. A partir d’un jeu de données obtenues à partir de compteurs intelligents dans un quartier de Wavre (en collaboration avec AREWAL, GreenWatch, Haulogy et ULB), nous avons simulé différentes communautés énergétiques virtuelles, de différentes tailles et avec différents horizons historiques. Pour chaque communauté virtuelle, nous avons entraîné un modèle prédictif relativement simple - basé sur de l’autorégression linéaire régularisée - permettent de prévoir la consommation électrique 24h plus tard, et avons ensuite évalué la qualité de ces prévisions.
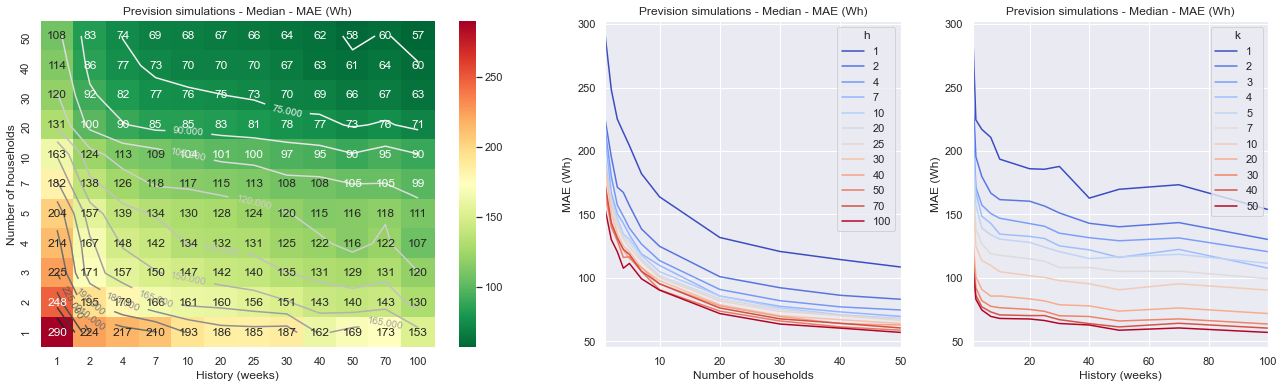
Les graphes ci-dessous synthétisent les résultats de l’analyse, indiquant les performances (MAE = erreur moyenne absolue des prévisions, en Watt*heure) que l’on peut espérer des prévisions sur une communauté, en fonction du nombre de ménages inscrits, et de la quantité de données historiques. On remarque ainsi qu’une vingtaine de foyers, ainsi qu’un historique d’environ six mois permettent d’obtenir un modèle relativement stable. La qualité du modèle peut néanmoins être améliorée davantage par l’inscription de nouveaux consommateurs, et par l’augmentation continue de l’historique de données.