
L’utilisation du contenu des articles de Wikipedia est fréquente dans les recherches académiques mais aussi, de plus en plus, pour des applications professionnelles. Les modalités pratiques d’exploitation sont cependant rarement analysées et présentées. Voici un bref retour d’expérience sur la question.
Wikipedia est une encyclopédie multilingue et collaborative lancée en 2001. Le volume de l’encyclopédie n’a cessé de grandir depuis sa création. En janvier 2013, les plus grosses éditions de Wikipedia étaient les éditions anglophone (plus de quatre millions d’articles), germanophone (plus d’un million et demi d’articles), francophone (plus d’un million trois cent mille articles) et néerlandophone (plus d’un million cent mille articles). Sa principale particularité est à rechercher du côté des modalités de création du contenu. Cette encyclopédie libre est en effet alimenté par des milliers de contributeurs bénévoles.
Publié sous licence libre (CC-BY-SA), Wikipedia constitue une ressource pour les chercheurs et les développeurs travaillant sur des problèmes de bases de données, d’indexation ou de classification de documents. La BBC l’a par exemple utilisée pour permettre l’interconnexion des informations présentes dans ses bases de données internes et leur enrichissement par des sources de données externes (principe du "Linked Data"). Reste que les modalités pratiques d’exploitation du contenu de Wikipedia sont peu connues...
Trois approches peuvent être exploitées pour accéder au contenu de l’encyclopédie.
Premièrement, il est possible de télécharger des copies de la base de données ("Database Dump") et d’en exploiter localement le contenu. Une page dédiée documente le Wikipedia:Database download. Cette piste doit obligatoirement être suivie si vous souhaitez travailler sur la totalité ou sur une partie importante du contenu de l’encyclopédie.
Deuxièmement, il est possible de réaliser un crawl de l’encyclopédie et d’ensuite analyser le contenu des articles. Il est possible de travailler, non pas sur des documents HTML, mais sur des documents textuels en syntaxe Mediawiki. Ces derniers sont plus faciles à analyser. Cette piste peut être suivie pour l’extraction de contenus ciblés. Les crawls d’envergure importante doivent par contre être évités, de manière à ne pas stresser les serveurs de Wikipedia. Cette précaution est d’ailleurs rappelée par l’encyclopédie : "Please do not use a web crawler to download large numbers of articles. Aggressive crawling of the server can cause a dramatic slow-down of Wikipedia".
Troisièmement, il est possible de procéder à des requêtes sur DBpedia. DBpedia est un effort communautaire qui a démarré en 2007. Il vise à extraire des informations structurées de Wikipedia et à les rendre disponibles sur Internet. Le contenu extrait depuis l’encyclopédie est converti dans le format RDF. Plusieurs mécanismes d’accès sont proposés pour explorer DBpedia : l’accès aux données RDF directement par URI (Universale Resource Identifier), l’utilisation d’agents Web (exemple : navigateurs pour le Web sémantique) et les points d’accès SPARQL permettant l’interrogation de DBpedia au moyen d’un langage évoquant le SQL utilisé pour les bases de données relationnelles.
![]()
A sa lecture, l’encyclopédie en ligne Wikipedia dégage une impression de structuration. En pratique, cependant, les contenus sont créés par des utilisateurs. Il en résulte des variations dans la catégorisation des articles, dans le balisage des informations, dans les conventions d’encodage des informations ou dans la présence ou non de certaines informations. Prenons deux exemples : les dates et les Infobox.
La syntaxe pour l’encodage des dates est variable d’un article à l’autre. Si l’on prend par exemple des fiches biographiques, on constate qu’une date de naissance peut être écrite en chiffres, ou avec le mois écrit en toutes lettres, accompagnée ou non d’informations complémentaires comme le lieu de naissance ou la profession. Cette variabilité est observable dans le corps des articles mais aussi dans celui des Infobox.
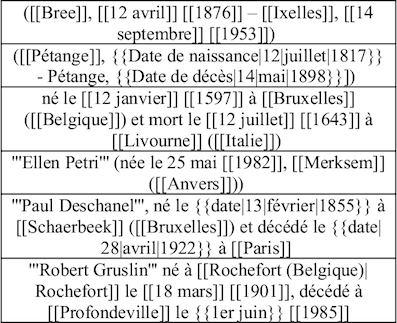
Les Infobox correspondent au tableau reprenant des informations factuelles et structurées en haut à droite de certains articles. Le contenu de ces Infobox est une base pour l’alimentation de la base de données DBpedia. La présence de ces Infobox est cependant limitée. Dans le cas des articles biographiques, moins d’un article sur trois propose ainsi un Infobox. Les biographies font pourtant partie d’un des types d’articles les plus fréquents sur Wikipedia. Les Infobox peuvent également varier, d’un article à l’autre, dans leur contenu (conventions) ou leur structure. Ainsi, le problème d’hétérogénéité des formats de date s’y retrouve. On peut observer en plus des variabilités dans le nom des entrées de l’Infobox. Une date de naissance pourra ainsi être étiquetée de différentes manières (un peu comme si un champs dans une base de données se retrouvait sous différents noms).
A l’origine alimenté par le contenu des Infobox et basé sur les contenus anglophones, DBpedia ne permet pas de disposer d’un contenu exhaustif sur un thème précis. Son contenu est cependant amené à se développer, au fur et à mesure que les extracteurs sont améliorés, que la structuration de l’encyclopédie progresse et que les différentes versions linguistiques de DBpedia gagnent en maturité. Reste que DBpedia est un outil de travail à privilégier pour les applications nécessitant une vaste quantité de ressources catégorisées (développement de systèmes de classement automatique, par exemple). Son utilisation nécessitera par contre une bonne maîtrise du langage d’interrogation SPARQL et une connaissance a priori de l’hétérogénéité de l’information au sein de DBpedia.
Le contenu des articles peut être extrait (depuis les Dumps ou sur base d’un Crawl ciblé) et analysé. L’exploitation d’outils standards d’extraction d’entités nommées est envisageable si les informations souhaitées sont suffisamment génériques (voir les catégories ENAMEX). Un outil comme le logiciel libre OpenNLP pourra par exemple être appliqué aux articles en anglais. Le développement d’extracteurs plus spécialisés pourront être développés avec des jeux d’expressions régulières, en s’appuyant sur les tournures de phrases spécifiques propres aux articles de l’encyclopédie. Le travail de revue et de structuration de l’encyclopédie tend en effet à en homogénéiser les contenus, sans que cette homogénéisation soit parfaite. Le développeur doit donc composer avec une information incomplète et l’existence de jeux de conventions différents utilisés simultanément.
Pour plus d’informations sur cette approche, voir : Robert Viseur (2013), Extraction de données biographiques depuis Wikipedia, Actes du 31ème colloque INFORSID, Paris, 29-31 mai 2013.
Signalons également l’existence de liens entre articles ou entre versions linguistiques, pouvant faciliter certains traitements. Un projet lancé en 2012 devrait également faire parler de lui à l’avenir. Il s’agit de Wikidata : "Wikidata is a free knowledge base that can be read and edited by humans and machines alike. It is for data what Wikimedia Commons is for media files : it centralizes access to and management of structured data, such as interwiki references and statistical information. Wikidata contains data in every language supported by the MediaWiki software". Le projet bénéficie d’un budget de plus d’un million d’euros. Il devrait notamment permettre d’améliorer la mise à jour de données factuelles présentes dans Wikipedia.
La qualité des données créés par les utilisateurs est largement discutée depuis quelques années. Ce débat n’est pas sans rappeler celui qui l’a précédé au début des années 2000 à propos de la qualité des logiciels open source... Il s’applique aujourd’hui à des projets tels que Wikipedia ou OpenStreeMap (un concurrent libre à Google Maps).
Des réflexions sont menées pour mesurer la qualité globale des articles de Wikipedia ou pour la prédire. Des critères tels que le nombre de mots, le nombre d’éditions, le nombre de contributeurs ou encore le nombre de références externes sont ainsi utilisés. Pour des données précises telles que les dates, le taux d’erreur (suite à une comparaison à des bases de données de référence) semble tourner autour des 2%.
Pour plus d’informations à ce sujet, voir : Robert Viseur (2013), "Collecter des données sur Wikipédia : application à la création d’une base de données biographiques", Journée d’étude WEUSC ("Wikipedia : évaluation et usages des savoirs collaboratifs"), Institut des sciences de la communication (ISCC) du CNRS, 5 juin 2013.