
Pourquoi lire cet article ?
Date: 19 mars 2025
Expertises
Domaine
Auteurs
Assurer une haute qualité des données est essentiel pour les organisations cherchant à générer de la valeur commerciale grâce à l’analyse et à l’apprentissage automatique. Une mauvaise qualité des données, due à des incohérences, des inexactitudes ou des informations manquantes, peut compromettre la prise de décision stratégique et l’efficacité des produits basés sur les données. Lorsque les entreprises ne peuvent pas faire confiance à leurs données, elles ont du mal à faire confiance aux insights qu’elles produisent. Comme le dit l’adage, "pas de données vaut mieux que des mauvaises données". Cela souligne le rôle crucial de la qualité des données en tant que pilier de la gouvernance des données, garantissant la fiabilité, la conformité et le succès global de l’entreprise.
a. Gestion du cycle de vie des données
Lors de la construction d’une plateforme de données, il est crucial de considérer six couches fondamentales et interconnectées :
À mesure que les architectures évoluent pour supporter des cas d’utilisation plus avancés, des couches supplémentaires peuvent être introduites en fonction des besoins spécifiques de l’équipe de données.
b. Dimensions de la qualité des données
Dimensions
Différents indicateurs définissent les dimensions de la qualité des données, servant de fondement aux approches modernes de la gestion de la qualité. Ces dimensions garantissent l’intégrité et la fiabilité des données dans les processus organisationnels. Les six dimensions clés de la qualité des données sont : l’exhaustivité, la ponctualité, la validité, l’exactitude, la cohérence et l’unicité.
En privilégiant ces dimensions, les organisations peuvent améliorer la qualité, la fiabilité et l’efficacité de leurs stratégies de gestion des données.
Workflow
Les problèmes de qualité des données doivent être priorisés en fonction de facteurs tels que l’impact sur les affaires et la complexité. Cette approche permet une résolution plus efficace des problèmes identifiés. Une approche bien établie pour améliorer la qualité des données est un cycle d’amélioration.
Le processus d’amélioration de la qualité des données commence par la définition claire de la portée du projet afin d’établir des objectifs et de se concentrer sur la surveillance continue et l’amélioration de la qualité de celles-ci. Ce workflow se compose de cinq phases séquentielles : définition, mesure, analyse, amélioration et contrôle, comme illustré dans la figure 1.
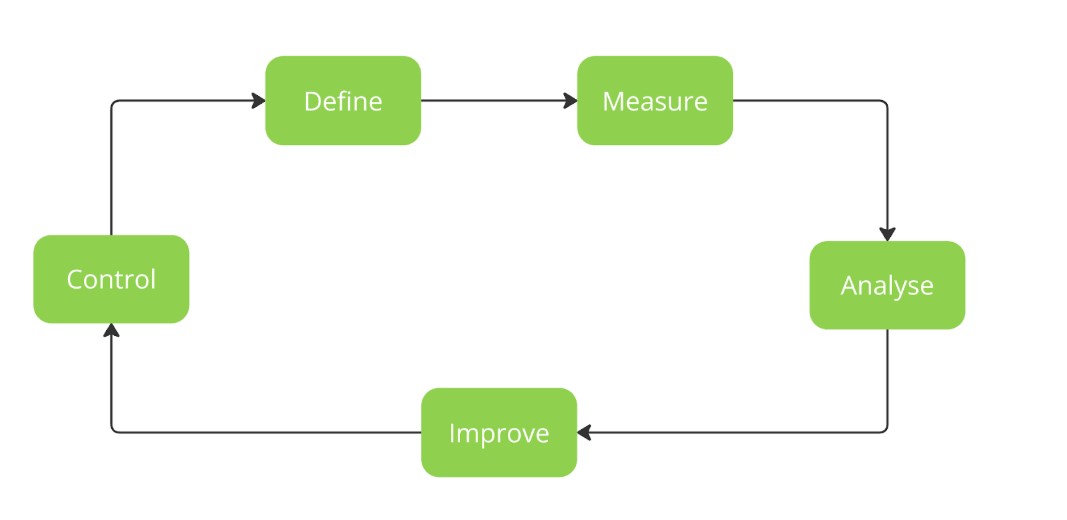
Définition : Définir la portée du projet en sélectionnant les ensembles de données pertinents et en déterminant les attributs nécessaires.
Mesure : Exprimer les dimensions de la qualité des données en termes mesurables et évaluer les erreurs. Utiliser des métriques pour communiquer l’état de la qualité des données et suivre les améliorations.
Analyse : Identifier les causes profondes des inexactitudes des données par le regroupement des erreurs et l’analyse des événements. Évaluer les problèmes systémiques dans la saisie et le traitement des données.
Amélioration : Développer et mettre en œuvre des solutions pour traiter les causes profondes, telles que des règles de validation et la réingénierie des processus.
Contrôle : Surveiller et valider l’efficacité des solutions mises en œuvre à l’aide de graphiques de contrôle et de règles métier. Assurer une amélioration continue en réévaluant systématiquement la qualité des données.
a. Analyse comparative
Plusieurs outils sont disponibles pour garantir la qualité des données dans les piles de données modernes. Voici une brève analyse comparative de quelques acteurs clés :
| Soda Core | Monte Carlo | Great Expectations | dbt | |
|---|---|---|---|---|
| Fonctionnalités Clés | Vérifications de qualité des données, surveillance, alertes, détection d’anomalies | Observabilité des données, détection d’anomalies, gestion des incidents, analyse des causes profondes | Tests de données, documentation et validation, profilage des données | Transformation des données, tests et documentation, gouvernance des données |
| Intégration | Diverses sources de données, API, pipelines de données | Entrepôts de données (Snowflake, BigQuery, etc.) | Diverses sources de données, pipelines de données | Entrepôts de données (Snowflake, BigQuery, etc.) |
| Automatisation | Vérifications automatisées, exécutions planifiées, alertes d’anomalies | Détection automatisée des anomalies, alertes, suivi des incidents | Tests automatisés, règles de validation, documentation des données | Tests automatisés dans le cadre du flux de travail de transformation |
| Évolutivité | Évolutif pour les grands ensembles de données | Conçu pour les environnements de données à grande échelle | Évolutif en fonction de l’infrastructure sous-jacente | Évolue avec l’entrepôt de données |
| Intégration avec Orchestrateur | Airflow, Prefect, Dagster | Airflow, Prefect, Dagster | Airflow, Prefect, Dagster | Airflow, Prefect, Dagster |
| Fonctionnement | Fichiers YAML pour la configuration | Propriétaire | Fichiers de configuration Python SQL | Fichiers SQL et YAML |
| Open Source ? | Oui | Non | Oui | Non |
b. Intégration de la qualité dans un pipeline de données
L’intégration de la qualité dans un pipeline de données est cruciale pour garantir des produits de données fiables. Voici comment ces outils peuvent être intégrés :
Où placer les vérifications de qualité des données :
Intégration avec les orchestrateurs : les outils comme Soda, Great Expectations et dbt peuvent être facilement intégrés avec des orchestrateurs. Cela permet d’automatiser les vérifications de qualité des données dans le flux du pipeline. Par exemple, les tests dbt peuvent faire partie d’un job dbt dans Airflow, et les vérifications Soda peuvent être déclenchées en tant que tâche dans un DAG Airflow.
Automatisation et surveillance : Automatiser les vérifications de qualité des données et surveiller en continu leur état. Les outils peuvent être utilisés pour intégrer les métriques de qualité des données avec des systèmes de surveillance comme Grafana, permettant leur observabilité complète. Cela peut générer des alertes et fournir des vues de tableau de bord pour la surveillance.
Exemple de Workflow : Dans un pipeline typique :
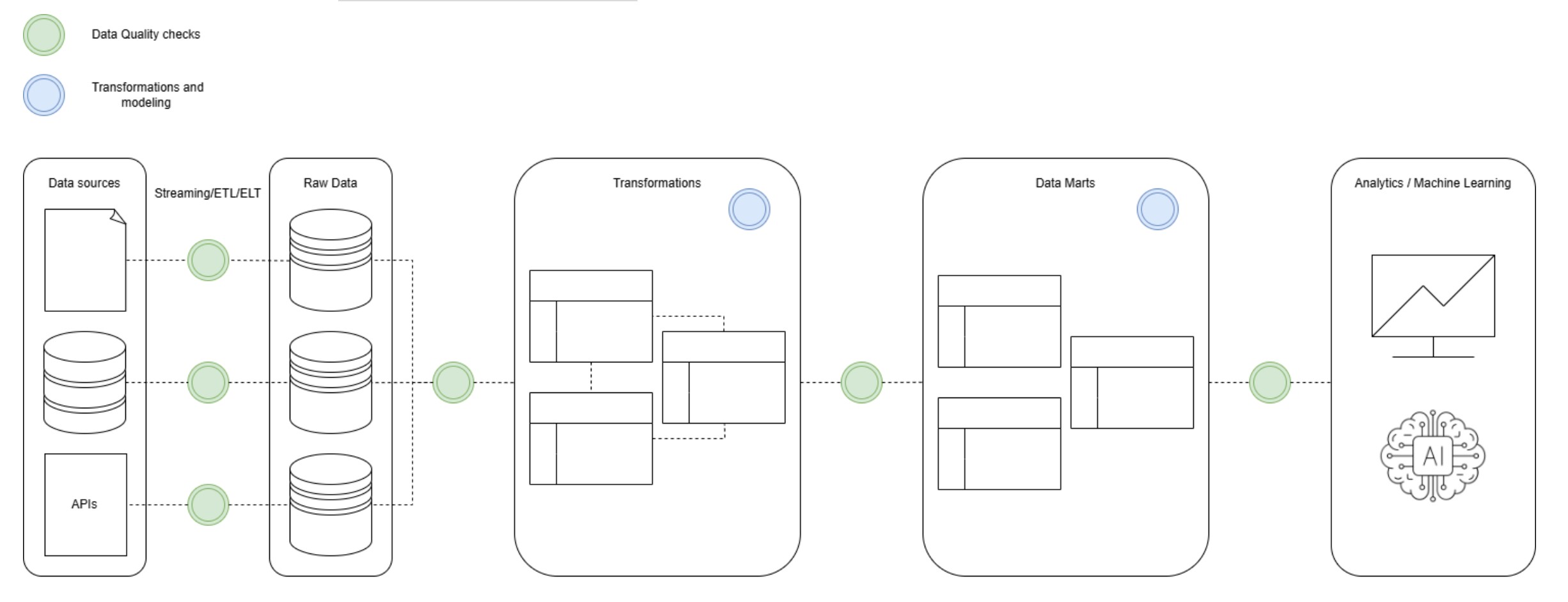
Cette intégration garantit que la qualité des données est maintenue tout au long du pipeline et que tout problème est détecté et traité rapidement.
Les flux de données fiables et les produits qu’ils permettent sont cruciaux pour garantir que les utilisateurs font confiance aux applications pour délivrer de la valeur. Construire des données fiables est un effort à long terme qui s’étend sur plusieurs étapes du pipeline de données. De plus, l’amélioration de la qualité des données n’est pas seulement un défi technique, mais aussi un engagement organisationnel et culturel.